 มาทำความรู้จักความสนุกสนานของการเล่น สล็อต กับ hengjing168
มาทำความรู้จักความสนุกสนานของการเล่น สล็อต กับ hengjing168
 สล็อต เป็นเกมที่สมควรสำหรับนักพนัน ที่ชอบใจความสนุก และสามารถได้กำไรได้โดยง่าย ซึ่งวันนี้พวกเราจะพามาทำความรู้จัก กลับเว็บไซต์สล็อตที่ดีเยี่ยมที่สุด โดยเว็บนี้เป็นเว็บไซต์ที่พิจารณาถึงผู้ใช้งาน เหตุเพราะพวกเรามีบริการที่ช่วยให้นักพนัน สามารถใช้งานเกมสล็อตที่นำเข้ามาจากต่างแดน ความสนุกสนานร่าเริงของเว็บนี้คือไม่เหมือนกัน ของการรวบรวมเกมการพนันจากทุกค่ายดัง จัดหนักจัดเต็มอีกทั้งในเรื่องของคุณภาพแล้วก็ เอฟเฟกต์ รวมไปถึงระบบที่เราได้ถ่ายทอดให้กับสมาชิกได้รับชม ทำให้นักพนันที่มาใช้งานเข้ามาร่วมสนุกกับเกมการเดิมพันยอดฮิตได้อย่างเต็มประสิทธิภาพ
สล็อต เป็นเกมที่สมควรสำหรับนักพนัน ที่ชอบใจความสนุก และสามารถได้กำไรได้โดยง่าย ซึ่งวันนี้พวกเราจะพามาทำความรู้จัก กลับเว็บไซต์สล็อตที่ดีเยี่ยมที่สุด โดยเว็บนี้เป็นเว็บไซต์ที่พิจารณาถึงผู้ใช้งาน เหตุเพราะพวกเรามีบริการที่ช่วยให้นักพนัน สามารถใช้งานเกมสล็อตที่นำเข้ามาจากต่างแดน ความสนุกสนานร่าเริงของเว็บนี้คือไม่เหมือนกัน ของการรวบรวมเกมการพนันจากทุกค่ายดัง จัดหนักจัดเต็มอีกทั้งในเรื่องของคุณภาพแล้วก็ เอฟเฟกต์ รวมไปถึงระบบที่เราได้ถ่ายทอดให้กับสมาชิกได้รับชม ทำให้นักพนันที่มาใช้งานเข้ามาร่วมสนุกกับเกมการเดิมพันยอดฮิตได้อย่างเต็มประสิทธิภาพ
วิถีทางการเข้าเล่นเกมสล็อตออนไลน์ที่ดีเยี่ยมที่สุด
 พวกเราได้มีการเปิดทางทาง ให้สามารถเข้าใช้งานเกมสล็อตเว็บตรงของพวกเราได้โดยสวัสดิภาพ ระบบนี้เป็นหนทางการเข้าเล่น ที่ส่งตรงจากทางค่ายผู้สร้างเว็บไซต์ ถึงเว็บไซต์ไซด์ของเราจะเป็นเว็บคาสิโนออนไลน์รวมเกม บริการที่พวกเราได้มุ่งเน้น ให้นักพนันได้ใช้งานผ่านหนทางเข้าเล่นของเราอย่างเต็มรูปแบบ ด้วยขนาดของเว็บไซต์ที่รองรับผู้ใช้งานได้มากที่สุด ทำให้วิถีทางเข้าเล่นเกมสล็อตออนไลน์บนเว็บนี้ สร้างกำไรได้จากผู้เล่น และได้นำมาพัฒนาให้นักเดิมพัน สามารถใช้บริการกับทางเว็บไซต์นี้ผ่านวิถีทางเข้าเล่นที่ทำเงินได้มากที่สุด ยิ่งไปกว่านี้เรายังมีการคืนผลกำไร ให้กับนักเดิมพันที่เลือกเข้ามาใช้งานกับเรา โดยมีอีกทั้งโปรโมชั่นที่อำนวยความสะดวก และพร้อมเป็นเว็บทำเงินสร้างรายได้ ที่นักพนันทุกคนรู้จักกันดี เป็นเว็บคาสิโนออนไลน์ที่ประจักษ์ ในประเทศไทย
พวกเราได้มีการเปิดทางทาง ให้สามารถเข้าใช้งานเกมสล็อตเว็บตรงของพวกเราได้โดยสวัสดิภาพ ระบบนี้เป็นหนทางการเข้าเล่น ที่ส่งตรงจากทางค่ายผู้สร้างเว็บไซต์ ถึงเว็บไซต์ไซด์ของเราจะเป็นเว็บคาสิโนออนไลน์รวมเกม บริการที่พวกเราได้มุ่งเน้น ให้นักพนันได้ใช้งานผ่านหนทางเข้าเล่นของเราอย่างเต็มรูปแบบ ด้วยขนาดของเว็บไซต์ที่รองรับผู้ใช้งานได้มากที่สุด ทำให้วิถีทางเข้าเล่นเกมสล็อตออนไลน์บนเว็บนี้ สร้างกำไรได้จากผู้เล่น และได้นำมาพัฒนาให้นักเดิมพัน สามารถใช้บริการกับทางเว็บไซต์นี้ผ่านวิถีทางเข้าเล่นที่ทำเงินได้มากที่สุด ยิ่งไปกว่านี้เรายังมีการคืนผลกำไร ให้กับนักเดิมพันที่เลือกเข้ามาใช้งานกับเรา โดยมีอีกทั้งโปรโมชั่นที่อำนวยความสะดวก และพร้อมเป็นเว็บทำเงินสร้างรายได้ ที่นักพนันทุกคนรู้จักกันดี เป็นเว็บคาสิโนออนไลน์ที่ประจักษ์ ในประเทศไทย
สายล่าโปรโมชั่น ยอมรับได้ไม่อั้นในเว็บไซต์ที่การพนัน
สำหรับนักเดิมพันที่ต้องการเข้าใช้บริการ จำต้องบอกเลยว่าสายล่าโปรโมชั่นห้ามพลาดอย่างไม่ต้องสงสัย เพราะพวกเรามีการเตรียมพร้อมโปรโมชั่น ให้ท่านได้รับอย่างงี้อั้น ใช้งานได้กับเว็บแห่งการเดิมพันที่เป็นมากกว่า เว็บไซต์ปกติที่เปิดขึ้นมา เนื่องจากว่าพวกเราเป็นเว็บตรงที่เปิดให้นักเดิมพันได้ใช้งาน ที่คิดถึงประสิทธิภาพของผู้ใช้งานเป็นลำดับแรก มาดูกันว่าโปรโมชั่นจะมีอะไรบ้าง
• สมัครเข้าใช้บริการรับเครดิตฟรี 250% มากยิ่งกว่าที่แห่งไหนแน่นอน !!
• ทุกยอดฝาก รับเลย 10% สูงสุดถึง 1 แสนบาท
• เชื้อเชิญเพื่อนรัก รับโชคสองเท่า รับเครดิตฟรี 100 บาท + รับยอดเสียเพื่อนพ้อง 5%
• วงล้อมหาเฮง !! หมุนปุบปับรับปั๊บไม่ติดเทิร์น
นี่เป็นเพียงแต่ โปรโมชั่นส่วนใดส่วนหนึ่งพื้นที่เว็บไซต์ของพวกเราตระเตรียมไว้ให้ กล่าวได้ว่าเป็นโปรโมชั่น ที่แจกให้กับสมาชิกพิเศษที่สุด แตกต่างจากเว็บไซต์อื่น อย่าเสียโอกาสทอง ลองเล่นกับเว็บแสนโชคดี
ลักษณะเด่นของการเข้าใช้บริการกับเว็บนี้นอกเหนือจากโปรโมชั่นแล้วมีอะไรบ้าง
สำหรับลักษณะเด่นของ ค่ายเกมการพนัน เว็บตรงแห่งนี้เว้นแต่มีโปรโมชั่นสุดดีเลิศแล้ว เรายังมี จุดแข็งของเว็บไซต์แห่งนี้ ที่ต้องการให้เขามาทดลองเล่นกับเว็บสุดโชคดี
1. ลงทะเบียนฟรีผ่านหน้าเว็บของเราโดยตรง
2. บริการผ่านเว็บตรง ทำรายการรวดเร็วทันใจ
3. มีคณะทำงานรอตอบคำถาม 1 วัน
4. ลงเดิมพันด้วยเงินลงทุนน้อย
5. โปรโมชั่นจุใจ จัดให้ก่อนคนใดกัน
6. ระบบเข้าถึงง่ายรองรับทุกวัสดุอุปกรณ์อิเล็กทรอนิกส์
สมัครเล่นสล็อตออนไลน์ บริการครบจบที่เดียว
หากคุณกำลังมองหาค่ายเกม การเดิมพันที่มีความครบจบในที่เดียว พวกเราขอแนะนำให้ท่านได้ทำความรู้จักกับค่ายเกมของเรา สล็อต ค่ายเกมการเดิมพันคาสิโนออนไลน์ที่เป็นที่รู้จักเยอะที่สุดเดี๋ยวนี้ โดยทางค่ายเกมการเดิมพันแห่งนี้มีนักเดิมพันเยอะมากต่างหลั่งไหลเข้ามาใช้บริการ เนื่องด้วยมีการรีวิวและก็บอกต่อจากผู้ใช้งาน ที่เข้ามาใช้บริการกับทางเว็บนี้โดยตรง ซึ่งถ้ามีคำถามว่าดีไหม ก็ต้องบอกเลยว่าเว็บของเรามีบริการที่ครบจบในที่เดียว ทั้งยังยังมีโปรโมชั่นจัด เตรียมไว้ให้กับสมาชิกที่เข้ามาใช้บริการมากที่สุด
กล่าวได้ว่านักพนันที่เลือกเข้าใช้บริการกับทางเว็บไซต์นี้ คุณจะมีตัวช่วยในการเข้าถึงเกมการพนันสล็อตเว็บตรง และก็สามารถลงพนันเกมคาสิโนออนไลน์ได้อย่างดีเยี่ยม ช่วยให้เข้าถึงเงินรางวัลบนเว็บแห่งนี้ได้อย่างสะดวกสบาย โดยแม้คุณพึงพอใจสามารถร่วมลงพนันกับทางเว็บไซต์ของพวกเราเว็บไซต์ที่เปิดให้บริการเกมคาสิโนออนไลน์ด้วยความมั่นคง มาร่วมเป็นส่วนใดส่วนหนึ่งกับเว็บไซต์ของพวกเราเพื่อเล่นเกมคาสิโนออนไลน์อย่างเต็มรูปแบบ และรับชมความไม่เหมือนที่ทางเว็บของเราได้ตระเตรียมไว้ให้ ผ่านทางการสมัครสมาชิกเพื่อร่วมรวมทั้งรับโปรโมชั่นสุดพิเศษ หนสมาชิกเท่านั้นที่จะได้รับผ่านทางเว็บของเรา
ตัวช่วยที่เยี่ยมที่สุดสำหรับสมาชิก ลงพนันสล็อตออนไลน์แบบคุ้ม
การเล่นเกมสล็อตเว็บตรงออนไลน์ผ่านทางค่ายเกม สล็อต168เว็บตรง โดยเว็บไซต์ของเรามีการตระเตรียมโปรโมชั่นสุดพิเศษไว้ให้กับสมาชิกอยู่ตลอด โดยนักพนันที่เข้ามาใช้บริการกับทาง เว็บไซต์เกมสล็อตแห่งนี้ ต่างบอกเป็นเสียงเดียวกันว่าเมื่อลงทะเบียนเป็นสมาชิกเข้ามาจะได้รับโปรโมชั่น เป็นการจัดโปรโมชั่นที่มีนานาประการแบบเตรียมพร้อมไว้ให้กับสมาชิก เพื่อให้นักพนันสามารถสัมผัสถึงเงินรางวัลได้ง่ายเพิ่มขึ้น เพราะเหตุว่าทางเว็บของพวกเราเป็นตัวช่วยที่มีการจัดเครดิตฟรี พร้อมด้วยแจกให้กับนักเดิมพันอยู่เสมอ ไม่เพียงแค่ครั้งแรกที่คุณทำการลงทะเบียนสมัครสมาชิกเข้ามาใช้งานแค่นั้น คุณจะได้รับโปรโมชั่นรวมทั้งสิ่งที่ช่วยอำนวยความสะดวกให้กับคุณได้มากมาย เพราะว่าเว็บของเราอยากเป็นเว็บไซต์ที่มีมาตรฐาน แล้วก็เป็นเว็บไซต์อันดับที่หนึ่งที่มีบริการที่ดีที่สุดนั่นเอง
เว็บสล็อตอันดับ 1 สล็อต168 m.Hengjing168.win 21 AUG 2566 Albert casino สล็อต168ที่ฮิตที่สุด Top 22
ขอขอบคุณมากอ้างอิง สล็อต
https://bit.ly/hengjing168-win
https://rebrand.ly/hengjing168-win

 เชิญชวนเพื่อนพ้องฝาก 100 จาก ดาวน์โหลด918kiss
เชิญชวนเพื่อนพ้องฝาก 100 จาก ดาวน์โหลด918kiss 1. โปรโมชั่น เชิญเพื่อนฝาก 100
1. โปรโมชั่น เชิญเพื่อนฝาก 100


.png)


 มั่นใจได้เลยว่าดีเยี่ยมที่สุดแน่นอน
มั่นใจได้เลยว่าดีเยี่ยมที่สุดแน่นอน เว็บเด็ด ระดับนานาชาติ เชื่อเลยว่าคุ้มรวมทั้งดี
เว็บเด็ด ระดับนานาชาติ เชื่อเลยว่าคุ้มรวมทั้งดี ร้อนแรงสุดๆในปีนี้ก็จำเป็นต้องนี้เลย สล็อตแตกง่าย เว็บไซต์สล็อตเบอร์ 1 ของโลก ผู้เล่นจะได้เจอกับสีสันความอลังการ สมรรถนะยอดเยี่ยม มีเกมสล็อตให้เล่นนับพัน เลือกเล่นได้ตามสไตล์ แถมยังขึ้นชื่อด้าน สล็อตแตกง่าย กว่าเว็บไซต์ปกติ แตกบ่อยมาก จริงไม่ได้หลอกลวง เข้าเล่นได้กำไรได้วันแล้ววันเล่า ตื่นเต้นไปกับความล้ำยุคของฟังก์ชั่นใหม่ๆที่เว็บ สล็อตแตกง่าย ได้มีการปรับปรุงแก้ไขอยู่บ่อยมาก
ร้อนแรงสุดๆในปีนี้ก็จำเป็นต้องนี้เลย สล็อตแตกง่าย เว็บไซต์สล็อตเบอร์ 1 ของโลก ผู้เล่นจะได้เจอกับสีสันความอลังการ สมรรถนะยอดเยี่ยม มีเกมสล็อตให้เล่นนับพัน เลือกเล่นได้ตามสไตล์ แถมยังขึ้นชื่อด้าน สล็อตแตกง่าย กว่าเว็บไซต์ปกติ แตกบ่อยมาก จริงไม่ได้หลอกลวง เข้าเล่นได้กำไรได้วันแล้ววันเล่า ตื่นเต้นไปกับความล้ำยุคของฟังก์ชั่นใหม่ๆที่เว็บ สล็อตแตกง่าย ได้มีการปรับปรุงแก้ไขอยู่บ่อยมาก ยังมีมาตรฐานที่สุดยอด จ่ายเต็ม จ่ายแน่ๆ ไม่มีหักใดๆก็ตามทั้งหมดทั้งปวง นำเข้าเกม สล็อตแตกบ่อยครั้งที่สุด ลิขสิทธิ์แท้จากค่ายชั้นนำ เชื่อถือได้เลยว่าผู้เล่นจะบันเทิงใจกว่าที่เคยผ่านมา เข้าเล่นผ่านทาง สล็อตแตกง่าย ได้ทั้งวัน ถึงแม้ท่านจะเป็นมือใหม่ก็เล่นได้สบายๆปั่นสล็อตสุดฟิน แจ็คพอตแตกกระจายหลายเท่า ที่สำคัญยังมีระบบระเบียบ ฝาก-ถอน ออโต้ ที่ฉับไว สมัครเข้าเลยอย่ารอช้า ความสนุกยังคอยนอยู่อีกมากมาย
ยังมีมาตรฐานที่สุดยอด จ่ายเต็ม จ่ายแน่ๆ ไม่มีหักใดๆก็ตามทั้งหมดทั้งปวง นำเข้าเกม สล็อตแตกบ่อยครั้งที่สุด ลิขสิทธิ์แท้จากค่ายชั้นนำ เชื่อถือได้เลยว่าผู้เล่นจะบันเทิงใจกว่าที่เคยผ่านมา เข้าเล่นผ่านทาง สล็อตแตกง่าย ได้ทั้งวัน ถึงแม้ท่านจะเป็นมือใหม่ก็เล่นได้สบายๆปั่นสล็อตสุดฟิน แจ็คพอตแตกกระจายหลายเท่า ที่สำคัญยังมีระบบระเบียบ ฝาก-ถอน ออโต้ ที่ฉับไว สมัครเข้าเลยอย่ารอช้า ความสนุกยังคอยนอยู่อีกมากมาย QR Code ดียิ่งกว่า URL สร้างคิวอาร์โค้ด เช่นไร
QR Code ดียิ่งกว่า URL สร้างคิวอาร์โค้ด เช่นไร 1. สแกนคิวอาร์โค้ดรวดเร็วกว่าพิมพ์ URL สร้างคิวอาร์โค้ด
1. สแกนคิวอาร์โค้ดรวดเร็วกว่าพิมพ์ URL สร้างคิวอาร์โค้ด
 Slotxo24hr
Slotxo24hr  การเล่นสล็อตออนไลน์บางทีอาจเป็นประสบการณ์ที่บันเทิงใจและก็น่าเร้าใจ แต่การชนะบางทีอาจเกิดเรื่องที่ท้าทายน้อย แม้กระนั้น มีเคล็ดลับแล้วก็ยุทธวิธีบางสิ่งบางอย่างที่คุณสามารถใช้เพื่อเพิ่มโอกาสสำหรับในการชนะบนแพลตฟอร์ม Slotxo ของเรา เพราะเหตุใดและอย่างไรบ้าง ไปดูกัน!
การเล่นสล็อตออนไลน์บางทีอาจเป็นประสบการณ์ที่บันเทิงใจและก็น่าเร้าใจ แต่การชนะบางทีอาจเกิดเรื่องที่ท้าทายน้อย แม้กระนั้น มีเคล็ดลับแล้วก็ยุทธวิธีบางสิ่งบางอย่างที่คุณสามารถใช้เพื่อเพิ่มโอกาสสำหรับในการชนะบนแพลตฟอร์ม Slotxo ของเรา เพราะเหตุใดและอย่างไรบ้าง ไปดูกัน! สล็อตทดลอง ทางเข้าเล่น slotxo https://M.slotxo24hr.co 28 ก.พ. 66 Leilani หาเว็บสล็อต สล็อตxoสล็อต xo เวอร์ชั่นใหม่ Top 23
สล็อตทดลอง ทางเข้าเล่น slotxo https://M.slotxo24hr.co 28 ก.พ. 66 Leilani หาเว็บสล็อต สล็อตxoสล็อต xo เวอร์ชั่นใหม่ Top 23
 ถ้าหากผู้ใดกันต้องการจะทดสอบเล่นแอปฯ บาคาร่า ที่ไม่เหมือนกันของแต่ละคน บางคนอยากจจะเล่น เพื่อเอาความเพลิดเพลิน ทุเลาสมองที่เมื่อยล้า จากการทำงานมาตลอดทั้งวัน หรือบางบุคคลเล่นเพื่อเอาเงินรางวัลจากมัน ไปใช้จ่ายในชีวิตประจำวัน แม้กระนั้นไม่ว่าจะเหตุผลใดๆก็ตามมแม้กระนั้น ขั้นตอนฐานรากพวกเราจะต้องทราบไว้และประพฤติตามเช่นกันหมดเป็นหาเว็บไซต์ สมัคร sexyauto168.com ได้เลย
ถ้าหากผู้ใดกันต้องการจะทดสอบเล่นแอปฯ บาคาร่า ที่ไม่เหมือนกันของแต่ละคน บางคนอยากจจะเล่น เพื่อเอาความเพลิดเพลิน ทุเลาสมองที่เมื่อยล้า จากการทำงานมาตลอดทั้งวัน หรือบางบุคคลเล่นเพื่อเอาเงินรางวัลจากมัน ไปใช้จ่ายในชีวิตประจำวัน แม้กระนั้นไม่ว่าจะเหตุผลใดๆก็ตามมแม้กระนั้น ขั้นตอนฐานรากพวกเราจะต้องทราบไว้และประพฤติตามเช่นกันหมดเป็นหาเว็บไซต์ สมัคร sexyauto168.com ได้เลย เว็บสมัครบาคาร่าที่ดีแน่นอน ไม่ควรละเลย
เว็บสมัครบาคาร่าที่ดีแน่นอน ไม่ควรละเลย สมัครบาคาร่า ที่พวกเราสามารถหาเล่นได้ทั้งบนโทรศัพท์มือถือและคอมพิวเตอร์ ไม่ว่าจะเป็น Window iOS หรือ Android สามารถเล่นได้สิ่งเดียวกันหมด แต่ว่า iOS อาจจะมีปัญหาในการเล่นนิดนึง แต่ก็สามารถเล่นได้เช่นกัน การดาวน์โหลดก็สามารถไปโหลดได้ และก็นี้ก็มิได้มีแค่เพียง เว็บบาคาร่า แต่ว่ายังมีเกมยิงปลา สมัครบาคาร่าออนไลน์ แข่งม้า รวมทั้งเกมอื่นๆอีกไม่ต่ำกว่า 100 เกม เรียกได้ว่า พวกเราเล่นกับเว็บไซต์ เพียงเว็บเดียว ก็ครอบคลุมการพนันออนไลน์ทั้งหมดทั้งปวงที่ในโลกนี้มี และก็ที่สำคัญเป็นได้โปรโมชั่นสุดพิเศษจากทางเว็บไซต์อีกด้วย
สมัครบาคาร่า ที่พวกเราสามารถหาเล่นได้ทั้งบนโทรศัพท์มือถือและคอมพิวเตอร์ ไม่ว่าจะเป็น Window iOS หรือ Android สามารถเล่นได้สิ่งเดียวกันหมด แต่ว่า iOS อาจจะมีปัญหาในการเล่นนิดนึง แต่ก็สามารถเล่นได้เช่นกัน การดาวน์โหลดก็สามารถไปโหลดได้ และก็นี้ก็มิได้มีแค่เพียง เว็บบาคาร่า แต่ว่ายังมีเกมยิงปลา สมัครบาคาร่าออนไลน์ แข่งม้า รวมทั้งเกมอื่นๆอีกไม่ต่ำกว่า 100 เกม เรียกได้ว่า พวกเราเล่นกับเว็บไซต์ เพียงเว็บเดียว ก็ครอบคลุมการพนันออนไลน์ทั้งหมดทั้งปวงที่ในโลกนี้มี และก็ที่สำคัญเป็นได้โปรโมชั่นสุดพิเศษจากทางเว็บไซต์อีกด้วย หนังสืบสวน ดูหนังใหม่ https://www.movieskub.com 7 เมษา 23 Delphia โปรแกรมหนัง ดูหนังใหม่ดูฟรี24ชั่วโมง Top 2
หนังสืบสวน ดูหนังใหม่ https://www.movieskub.com 7 เมษา 23 Delphia โปรแกรมหนัง ดูหนังใหม่ดูฟรี24ชั่วโมง Top 2


 จุดแข็งที่เพราะเหตุไรจะต้องเล่นที่ดินเข้าpg ทางเข้าpg
จุดแข็งที่เพราะเหตุไรจะต้องเล่นที่ดินเข้าpg ทางเข้าpg • PG โปรโมชั่นร้อนแรง ฝาก100 รับ500 สำหรับคนทุนน้อย ทุกยอดฝากรับเครดิตเพียบ ใครที่มีงบน้อยไม่ต้องวิตกกังวลไปค่ะ เว็บไซต์ของเราพร้อมซัพเพียงพอรต์ทุกท่านอย่างดีเยี่ยมและเข้าใจเลยจ้ะ พวกเราเลยทำโปรโมชั่นนี้มาเอาอกเอาใจสายทุนน้อย
• PG โปรโมชั่นร้อนแรง ฝาก100 รับ500 สำหรับคนทุนน้อย ทุกยอดฝากรับเครดิตเพียบ ใครที่มีงบน้อยไม่ต้องวิตกกังวลไปค่ะ เว็บไซต์ของเราพร้อมซัพเพียงพอรต์ทุกท่านอย่างดีเยี่ยมและเข้าใจเลยจ้ะ พวกเราเลยทำโปรโมชั่นนี้มาเอาอกเอาใจสายทุนน้อย


 เว็บสล็อต punpro777 สล็อต777 ซึ่งทำให้พวกเราสามารถพัฒนาระบบการเล่นที่มีประสิทธิภาพซึ่งรองรับความต้องการของผู้เล่นทุกท่านอย่างไม่ต้องสงสัย เว็บไซต์พนันออนไลน์ ฝากถอนไม่มีอย่างต่ำ เป็นหนึ่งในผู้พัฒนาเกมคาสิโนออนไลน์ที่เหมาะสมที่สุด ด้วยเหตุว่าพวกเขาให้ความใส่ใจกับผู้เล่นเสมอ พวกเขามีชื่อเสียงกันดีสำหรับเกมต่างๆได้แก่ กางล็คแจ็ค วิดีโอโป๊กเกอร์ แล้วก็รูเล็ต เว็บพนันออนไลน์เว็บตรง ได้ปรับปรุงเกมคาสิโนหลายชนิดมากว่า 15 ปี และก็ยังถือเป็นหนึ่งในผู้นำในด้านนี้ เว็บคาสิโน ไม่ผ่านเอเย่นต์ เป็นเลิศในบริษัทการพนันออนไลน์ชั้นหนึ่งยอดนิยมเป็นอย่างมาก เพราะเหตุว่ามีเกมที่มากมายและเป็นเว็บคาสิโนออนไลน์เว็บไซต์ตรง ได้ปรับปรุงเกมอย่างต่อเนื่องมาเป็นเวลากว่า 20 ปี ซึ่งได้รับรางวัลมากมายก่ายกองในด้านคุณภาพ เว็บไซต์ตรงไม่ผ่านเอเย่นต์ ยังเป็นที่เข้าใจดีว่ามีบริการช่วยเหลือลูกค้าที่ยอดเยี่ยม ซึ่งช่วยในการสร้างประสบการณ์การเล่นเกมที่ราบระรื่นสำหรับผู้เล่น เว็บ
เว็บสล็อต punpro777 สล็อต777 ซึ่งทำให้พวกเราสามารถพัฒนาระบบการเล่นที่มีประสิทธิภาพซึ่งรองรับความต้องการของผู้เล่นทุกท่านอย่างไม่ต้องสงสัย เว็บไซต์พนันออนไลน์ ฝากถอนไม่มีอย่างต่ำ เป็นหนึ่งในผู้พัฒนาเกมคาสิโนออนไลน์ที่เหมาะสมที่สุด ด้วยเหตุว่าพวกเขาให้ความใส่ใจกับผู้เล่นเสมอ พวกเขามีชื่อเสียงกันดีสำหรับเกมต่างๆได้แก่ กางล็คแจ็ค วิดีโอโป๊กเกอร์ แล้วก็รูเล็ต เว็บพนันออนไลน์เว็บตรง ได้ปรับปรุงเกมคาสิโนหลายชนิดมากว่า 15 ปี และก็ยังถือเป็นหนึ่งในผู้นำในด้านนี้ เว็บคาสิโน ไม่ผ่านเอเย่นต์ เป็นเลิศในบริษัทการพนันออนไลน์ชั้นหนึ่งยอดนิยมเป็นอย่างมาก เพราะเหตุว่ามีเกมที่มากมายและเป็นเว็บคาสิโนออนไลน์เว็บไซต์ตรง ได้ปรับปรุงเกมอย่างต่อเนื่องมาเป็นเวลากว่า 20 ปี ซึ่งได้รับรางวัลมากมายก่ายกองในด้านคุณภาพ เว็บไซต์ตรงไม่ผ่านเอเย่นต์ ยังเป็นที่เข้าใจดีว่ามีบริการช่วยเหลือลูกค้าที่ยอดเยี่ยม ซึ่งช่วยในการสร้างประสบการณ์การเล่นเกมที่ราบระรื่นสำหรับผู้เล่น เว็บ สล็อต punpro777 สล็อต777 เป็นผู้พัฒนาซอฟต์แวร์คาสิโนรายหนึ่งที่ปรับปรุงฟีพบร์ใหม่ๆโดยตลอดซึ่งมีคุณประโยชน์ วันนี้รับฟรีโปรโมชั่นมากมายกมาย ไม่ว่าจะเป็นลูกค้าเก่าหรือลูกค้าใหม่ทางพวกเราจัดให้พิเศษสุดๆรับประกันสล็อตแตกง่ายกับ เว็บไซต์ตรงสล็อต ไม่ผ่านเอเย่นต์เว็บใหม่ เว็บสล็อตเว็บตรงน่าไว้วางใจ อัตราการชนะพนันพนันสล็อตที่สูงสูด เว็บสล็อตออนไลน์ฝากถอนไม่มีอย่างต่ำ ด้วยระบบอัตโนมัติที่ทันสมัย เว็บไซต์ของพวกเราดูแลทุกความอยากของผู้เล่นและแก้ไขพัฒนาให้เยี่ยมที่สุดเสมอ แล้วก็บริการอย่างสม่ำเสมอ เว็บพนันออนไลน์ ฝากถอนไม่มีขั้นต่ำ เป็นผู้พัฒนาเกมคาสิโนออนไลน์ที่เป็นที่รู้จัก เราได้รับความนิยมอย่างล้นหลาม เนื่องจากผลงานเยอะแยะที่เราปรับปรุงขึ้นนั้น เต็มไปด้วยคุณลักษณะที่น่าสนใจ เช่น แจ็คพอต แจ็คพอตที่ขึ้นอยู่กับทักษะของผู้เล่น เว็บไซต์คาสิโน ไม่ผ่านเอเย่นต์ หลายเกมที่ทำให้ผู้เล่นสามารถชนะรางวัลได้มากกว่าเงินตรงนี้ที่เดียวจะซื้อได้ในคาสิโนอื่นและก็อีกเยอะมาก บรรลุความสำเร็จอย่างดีเยี่ยม เว็บไซต์สล็อต punpro777 ริเริ่มตั้งขึ้นโดยเว็บไซต์ตรงไม่ผ่านเอเย่นต์ ในไทย เป็นผู้ให้บริการซอฟต์แวร์ที่เป็นที่รู้จักแล้วก็ตั้งความมุ่งหมาย เว็บพนันออนไลน์เว็บตรง ที่จะให้บริการที่ดีที่สุดบนอินเทอร์เน็ตแก่ผู้เล่นในตอนนี้ เพื่อค้ำประกันสิ่งนี้ พวกเขาได้พัฒนาผลิตภัณฑ์ใหม่รวมทั้งแก้ไขอย่างสม่ำเสมอ สำหรับแพลตฟอร์มเกมของพวกเขา ซึ่งรวมทั้งแอพมือถือล่าสุดสำหรับเกมเมอร์เพื่อเล่นบนสมาร์ทโฟนหรือแท็บเล็ตเป้าหมายหลักของ punpro777 สล็อตเป็นการนำเสนอผลิตภัณฑ์ที่ใหม่กว่า รวมทั้งดีกว่าที่สามารถปรับปรุงประสบการณ์ของผู้เล่นทั่วทั้งโลกเป็นผู้พัฒนา คาสิโนออนไลน์เว็บไซต์ตรงที่ได้รับความนิยมอย่างมากจากเกมต่างๆของเรา
สล็อต punpro777 สล็อต777 เป็นผู้พัฒนาซอฟต์แวร์คาสิโนรายหนึ่งที่ปรับปรุงฟีพบร์ใหม่ๆโดยตลอดซึ่งมีคุณประโยชน์ วันนี้รับฟรีโปรโมชั่นมากมายกมาย ไม่ว่าจะเป็นลูกค้าเก่าหรือลูกค้าใหม่ทางพวกเราจัดให้พิเศษสุดๆรับประกันสล็อตแตกง่ายกับ เว็บไซต์ตรงสล็อต ไม่ผ่านเอเย่นต์เว็บใหม่ เว็บสล็อตเว็บตรงน่าไว้วางใจ อัตราการชนะพนันพนันสล็อตที่สูงสูด เว็บสล็อตออนไลน์ฝากถอนไม่มีอย่างต่ำ ด้วยระบบอัตโนมัติที่ทันสมัย เว็บไซต์ของพวกเราดูแลทุกความอยากของผู้เล่นและแก้ไขพัฒนาให้เยี่ยมที่สุดเสมอ แล้วก็บริการอย่างสม่ำเสมอ เว็บพนันออนไลน์ ฝากถอนไม่มีขั้นต่ำ เป็นผู้พัฒนาเกมคาสิโนออนไลน์ที่เป็นที่รู้จัก เราได้รับความนิยมอย่างล้นหลาม เนื่องจากผลงานเยอะแยะที่เราปรับปรุงขึ้นนั้น เต็มไปด้วยคุณลักษณะที่น่าสนใจ เช่น แจ็คพอต แจ็คพอตที่ขึ้นอยู่กับทักษะของผู้เล่น เว็บไซต์คาสิโน ไม่ผ่านเอเย่นต์ หลายเกมที่ทำให้ผู้เล่นสามารถชนะรางวัลได้มากกว่าเงินตรงนี้ที่เดียวจะซื้อได้ในคาสิโนอื่นและก็อีกเยอะมาก บรรลุความสำเร็จอย่างดีเยี่ยม เว็บไซต์สล็อต punpro777 ริเริ่มตั้งขึ้นโดยเว็บไซต์ตรงไม่ผ่านเอเย่นต์ ในไทย เป็นผู้ให้บริการซอฟต์แวร์ที่เป็นที่รู้จักแล้วก็ตั้งความมุ่งหมาย เว็บพนันออนไลน์เว็บตรง ที่จะให้บริการที่ดีที่สุดบนอินเทอร์เน็ตแก่ผู้เล่นในตอนนี้ เพื่อค้ำประกันสิ่งนี้ พวกเขาได้พัฒนาผลิตภัณฑ์ใหม่รวมทั้งแก้ไขอย่างสม่ำเสมอ สำหรับแพลตฟอร์มเกมของพวกเขา ซึ่งรวมทั้งแอพมือถือล่าสุดสำหรับเกมเมอร์เพื่อเล่นบนสมาร์ทโฟนหรือแท็บเล็ตเป้าหมายหลักของ punpro777 สล็อตเป็นการนำเสนอผลิตภัณฑ์ที่ใหม่กว่า รวมทั้งดีกว่าที่สามารถปรับปรุงประสบการณ์ของผู้เล่นทั่วทั้งโลกเป็นผู้พัฒนา คาสิโนออนไลน์เว็บไซต์ตรงที่ได้รับความนิยมอย่างมากจากเกมต่างๆของเรา
 ขอขอบคุณby
ขอขอบคุณby 

 รูปแบบการใช้งานของ jubyet69 ดูหนังxมีระบบระเบียบอะไรที่มีคุณประโยชน์กับทุกคนบ้าง?
รูปแบบการใช้งานของ jubyet69 ดูหนังxมีระบบระเบียบอะไรที่มีคุณประโยชน์กับทุกคนบ้าง?

 สวัสดีนะครับชาว เว็บสล็อตอันดับ1 ทุกคน เป็นอย่างไรกันบ้างขอรับ ในบทความก่อนหน้าที่ผ่านมา ผมได้เขียนถึงเรื่อง ข้อดีของ
สวัสดีนะครับชาว เว็บสล็อตอันดับ1 ทุกคน เป็นอย่างไรกันบ้างขอรับ ในบทความก่อนหน้าที่ผ่านมา ผมได้เขียนถึงเรื่อง ข้อดีของ 1. ตั้งเป้าหมายสำหรับการเล่นพีจีสล็อตทุกหน
1. ตั้งเป้าหมายสำหรับการเล่นพีจีสล็อตทุกหน 2. กำหนดเงินทุนในแต่ละครั้งให้กระจ่าง
2. กำหนดเงินทุนในแต่ละครั้งให้กระจ่าง








 หนัง69 คลิปเด็ดห้ามพลาด พร้อมให้ทุกท่านได้คลิ๊กดูแล้วค่ะ
หนัง69 คลิปเด็ดห้ามพลาด พร้อมให้ทุกท่านได้คลิ๊กดูแล้วค่ะ
 สล็อต55 55สล็อต สล็อตยอดนิยม สล็อตเว็บไซต์ตรง888 55slot สล็อตเว็บตรงแท้
สล็อต55 55สล็อต สล็อตยอดนิยม สล็อตเว็บไซต์ตรง888 55slot สล็อตเว็บตรงแท้  กรรมวิธีการถอนเงินแบบง่ายๆตามฉบับ สล็อตเว็บตรงแท้ 55สล็อต
กรรมวิธีการถอนเงินแบบง่ายๆตามฉบับ สล็อตเว็บตรงแท้ 55สล็อต สล็อตpg 55สล็อต https://www.jinda55.com 4 Apr 23 Kimberley คาสิโน สล็อตยอดนิยมไม่มีโกง Top 80
สล็อตpg 55สล็อต https://www.jinda55.com 4 Apr 23 Kimberley คาสิโน สล็อตยอดนิยมไม่มีโกง Top 80
 มาดูหนัง GDH ที่ madoohd.com กันเถิด EP.2
มาดูหนัง GDH ที่ madoohd.com กันเถิด EP.2 สวัสดีครับชาว หนังชนโรง ทุกคน เป็นไงบ้างครับ กลับมาเจอกับผมแล้วก็บทความเว็บไซต์ดูหนังผ่านอินเตอร์เน็ตกับ มาดูหนัง GDH ที่ madoohd.com กันเถอะ EP.2 แล้วครับ ใน EP.1 ผมได้ชี้แนะให้ทุกคนไปแล้ว 5 เรื่องร่วมกัน
สวัสดีครับชาว หนังชนโรง ทุกคน เป็นไงบ้างครับ กลับมาเจอกับผมแล้วก็บทความเว็บไซต์ดูหนังผ่านอินเตอร์เน็ตกับ มาดูหนัง GDH ที่ madoohd.com กันเถอะ EP.2 แล้วครับ ใน EP.1 ผมได้ชี้แนะให้ทุกคนไปแล้ว 5 เรื่องร่วมกัน และสำหรับบทความที่ผมจะมานำเสนอในวันนี้ คนไหนกันที่ชอบการ
และสำหรับบทความที่ผมจะมานำเสนอในวันนี้ คนไหนกันที่ชอบการ



 ศูนย์รวมเกมส์การพนันสล็อตออนไลน์แตกง่าย ทางเข้าxo
ศูนย์รวมเกมส์การพนันสล็อตออนไลน์แตกง่าย ทางเข้าxo

 ทำไมจะต้องเล่นสล็อตเว็บไซต์ตรง สล็อตpgเว็บตรง
ทำไมจะต้องเล่นสล็อตเว็บไซต์ตรง สล็อตpgเว็บตรง สวัสดีขอรับชาว pgslot-1st.com ทุกท่าน เป็นอย่างไรกันบ้างขอรับ ผมหวังว่าทุกคนจะสบายดีและสุขภาพแข็งแรงครับผม ดังเดิมเลยขอรับ ช่วงนี้ฝุ่นผงจำนวนไม่ใช่น้อยทางที่ดีนะครับผม พยายามอย่าออกมาจากบ้านดีกว่า แต่ว่าถ้าหากจำเป็นต้องออกจากบ้าน ก็อย่าลืมสวมมาส์กด้วยครับ ด้วยความหวังดีจากผมและ pg slot ครับ ฮ่า… แม้กระนั้นถ้าคนใดกันแน่ไม่ได้อยากต้องการออกไปข้างนอกล่ะก็ อยู่บ้านนอนเล่นเกมสล็อตจาก pg ไปร่วมกันครับ ยืนยันเลยว่า เอนจอยแน่ๆครับผม!
สวัสดีขอรับชาว pgslot-1st.com ทุกท่าน เป็นอย่างไรกันบ้างขอรับ ผมหวังว่าทุกคนจะสบายดีและสุขภาพแข็งแรงครับผม ดังเดิมเลยขอรับ ช่วงนี้ฝุ่นผงจำนวนไม่ใช่น้อยทางที่ดีนะครับผม พยายามอย่าออกมาจากบ้านดีกว่า แต่ว่าถ้าหากจำเป็นต้องออกจากบ้าน ก็อย่าลืมสวมมาส์กด้วยครับ ด้วยความหวังดีจากผมและ pg slot ครับ ฮ่า… แม้กระนั้นถ้าคนใดกันแน่ไม่ได้อยากต้องการออกไปข้างนอกล่ะก็ อยู่บ้านนอนเล่นเกมสล็อตจาก pg ไปร่วมกันครับ ยืนยันเลยว่า เอนจอยแน่ๆครับผม! 1. สล็อตเว็บไซต์ตรงมีความน่าวางใจสูงมากมาย
1. สล็อตเว็บไซต์ตรงมีความน่าวางใจสูงมากมาย


 • สล็อตpgแท้ เรียนรู้เว็บไซต์สล็อตออนไลน์ที่จะเล่นก่อน ในยุคนี้ คนใดไม่เล่นสล็อตเว็บตรงนับว่าคุณพลาดแล้วนะครับ เนื่องจากการเล่นสล็อตออนไลน์ที่เป็นเว็บไซต์ตรงอย่างสล็อตpgแท้นั้นไม่มีอันตรายมากมายๆครับ คุณจะไม่จำเป็นที่จะต้องมาวิตกกังวลหรือกลุ้มใจว่า เล่นไปแล้วจะโดนล็อกผลไหม เล่นได้กำไรแล้วจะถอนได้ไหม ปัญหาพวกนี้จะไม่เกิดขึ้นกับสล็อตเว็บตรงแน่ๆนะครับ
• สล็อตpgแท้ เรียนรู้เว็บไซต์สล็อตออนไลน์ที่จะเล่นก่อน ในยุคนี้ คนใดไม่เล่นสล็อตเว็บตรงนับว่าคุณพลาดแล้วนะครับ เนื่องจากการเล่นสล็อตออนไลน์ที่เป็นเว็บไซต์ตรงอย่างสล็อตpgแท้นั้นไม่มีอันตรายมากมายๆครับ คุณจะไม่จำเป็นที่จะต้องมาวิตกกังวลหรือกลุ้มใจว่า เล่นไปแล้วจะโดนล็อกผลไหม เล่นได้กำไรแล้วจะถอนได้ไหม ปัญหาพวกนี้จะไม่เกิดขึ้นกับสล็อตเว็บตรงแน่ๆนะครับ •
•  พีจี pg168 https://www.berving.com 2 Sep 66 Norma รับเครดิต เล่นฟรี สล็อตpgแท้VIP Top 78
พีจี pg168 https://www.berving.com 2 Sep 66 Norma รับเครดิต เล่นฟรี สล็อตpgแท้VIP Top 78
 สำหรับคนที่มีความรู้สึกชื่นชอบหนังออนไลน์สำหรับการดูหนังผ่านเน็ต เป็นความรู้สึกนึกคิด มักอยากจะหาหนังดูหลายๆแบบ หลายๆเรื่อง และก็ปรารถนาความสนุกสนานแบบ 1 วัน ซึ่งการไปมองภาพยนตร์ในโรงไม่อาจจะตอบโจทย์ความต้องการได้ แล้วก็ตั้งแต่นี้ต่อไปก็คือเหตุผลว่าเพราะอะไรพวกเราถึงจำต้อง ดูหนังผ่านเน็ต กับเว็บไซต์ ดูหนัง
สำหรับคนที่มีความรู้สึกชื่นชอบหนังออนไลน์สำหรับการดูหนังผ่านเน็ต เป็นความรู้สึกนึกคิด มักอยากจะหาหนังดูหลายๆแบบ หลายๆเรื่อง และก็ปรารถนาความสนุกสนานแบบ 1 วัน ซึ่งการไปมองภาพยนตร์ในโรงไม่อาจจะตอบโจทย์ความต้องการได้ แล้วก็ตั้งแต่นี้ต่อไปก็คือเหตุผลว่าเพราะอะไรพวกเราถึงจำต้อง ดูหนังผ่านเน็ต กับเว็บไซต์ ดูหนัง  สำหรับคอหนังที่ถูกใจดูหนังดังบน Netflix ทางเว็บไซต์หนังออนไลน์ของเราก็อัพเดทมาให้แด่ท่านได้ดูหนังผ่านอินเตอร์เน็ตอย่างรวดเร็ว ท่านไม่มีความจำเป็นต้องเสียค่าใช้จ่ายในการสมัครสมาชิกรายเดือนอีกต่อไป ทางเว็บของเรานำหนังใหม่ชนโรง แล้วก็หนังดังที่มีคุณภาพมาให้ทุกท่านได้รับดูกัน เรียกได้ว่าไม่แพ้หนังบนเน็ตฟริกซ์อย่างยิ่งจริงๆ และก็ที่สำคัญเรามีหนังให้เลือกรับชมมากกว่าไม่ว่าจะในกระแส หรือนอกกระแส มั่นใจว่าทุกคนจะได้รับความเพลิดเพลินแบบเต็มที่ ครบทุกอรรถรส การเลือกดูหนังใหม่ๆไม่ใช่เรื่องยากอีกต่อไป เพียงแต่ไปที่ช่องค้นหา สามารถพิมพ์ชื่อหรือปีที่ฉาย ก็จะแสดงผลลัพธ์ลัพท์หนังที่ต้องการได้อย่างเร็ว
สำหรับคอหนังที่ถูกใจดูหนังดังบน Netflix ทางเว็บไซต์หนังออนไลน์ของเราก็อัพเดทมาให้แด่ท่านได้ดูหนังผ่านอินเตอร์เน็ตอย่างรวดเร็ว ท่านไม่มีความจำเป็นต้องเสียค่าใช้จ่ายในการสมัครสมาชิกรายเดือนอีกต่อไป ทางเว็บของเรานำหนังใหม่ชนโรง แล้วก็หนังดังที่มีคุณภาพมาให้ทุกท่านได้รับดูกัน เรียกได้ว่าไม่แพ้หนังบนเน็ตฟริกซ์อย่างยิ่งจริงๆ และก็ที่สำคัญเรามีหนังให้เลือกรับชมมากกว่าไม่ว่าจะในกระแส หรือนอกกระแส มั่นใจว่าทุกคนจะได้รับความเพลิดเพลินแบบเต็มที่ ครบทุกอรรถรส การเลือกดูหนังใหม่ๆไม่ใช่เรื่องยากอีกต่อไป เพียงแต่ไปที่ช่องค้นหา สามารถพิมพ์ชื่อหรือปีที่ฉาย ก็จะแสดงผลลัพธ์ลัพท์หนังที่ต้องการได้อย่างเร็ว
 การที่พวกเราเคลมตนเองว่าเป็นเว็บไซต์ ดูหนังผ่านอินเตอร์เน็ต หนังใหม่ ดูหนังผ่านอินเตอร์เน็ต 2023 ที่ยอดเยี่ยมในปีนี้ มันก็ไม่แปลก เพราะว่านอกเหนือจากระบบหน้าเว็บของพวกเราจะสะดวกรวมทั้งตามมาตรฐานสากลมากมายๆแล้ว พวกเรายังมีการจัดการระบบการดูหนังให้ทุกท่านได้ดูหนังที่ต้องการดูฟรีๆดูหนังผ่านเน็ต หนังใหม่ ดูหนังผ่านเน็ต 2023 กับเรา ทุกท่านจะอย่างกับได้ดูหนังในแพลทฟอร์มมีชื่อเยอะมาก ไม่ว่าจะเป็น Netflix Disney hotstar รวมทั้งอื่นๆเพราะพวกเรา เว็บ ดูหนังผ่านเน็ต หนังใหม่ ดูหนังผ่านอินเตอร์เน็ต 2023 Movie2k ต้องการที่จะให้ทุกคนได้ดูหนังผ่านเน็ตกันอย่างจุใจรวมทั้งคุ้มค่าที่จะดูที่สุด รวมทั้งทั้งผองที่บอกมา มันคือของแท้ ภาพคม ชัด ลึก เสียงเป๊ะ full HD ทุกเรื่องทุกตอน แถมเว็บไซต์ ดูหนังผ่านเน็ต หนังใหม่ ดูหนังผ่านอินเตอร์เน็ต 2023 ชองพวกเรา ยังอัพเดทหนังไวเยอะที่สุดในประเทศไทยอย่างไม่ต้องสงสัย เนื่องจากพวกเราจัดหนักจัดเต็มอีกทั้งหนังโรง หนังชนโรงพวกเราก็มี บางโอกาสมีหนังที่ยังไม่เข้าโรงที่เมืองไทยด้วย สุดจัดสุดจริง ดูหนังผ่านอินเตอร์เน็ต หนังใหม่ ดูหนังออนไลน์ 2023 กับพวกเรา movie2k จะมีผลให้ทุกคน ได้อัพเดทหนังก่อนคนใดกันแน่ ไม่ต้องมานั่งกลัวโดนสปอย เพราะเรา movie2k มีหนังให้ทุกคนได้ดูกันฟรีๆก่อนคนไหนกัน ดูหนังออนไลน์ หนังใหม่ ดูหนังออนไลน์ 2023 จำเป็นต้องนึกถึงเรา movie2k! ดูหนังหนังออนไลน์
การที่พวกเราเคลมตนเองว่าเป็นเว็บไซต์ ดูหนังผ่านอินเตอร์เน็ต หนังใหม่ ดูหนังผ่านอินเตอร์เน็ต 2023 ที่ยอดเยี่ยมในปีนี้ มันก็ไม่แปลก เพราะว่านอกเหนือจากระบบหน้าเว็บของพวกเราจะสะดวกรวมทั้งตามมาตรฐานสากลมากมายๆแล้ว พวกเรายังมีการจัดการระบบการดูหนังให้ทุกท่านได้ดูหนังที่ต้องการดูฟรีๆดูหนังผ่านเน็ต หนังใหม่ ดูหนังผ่านเน็ต 2023 กับเรา ทุกท่านจะอย่างกับได้ดูหนังในแพลทฟอร์มมีชื่อเยอะมาก ไม่ว่าจะเป็น Netflix Disney hotstar รวมทั้งอื่นๆเพราะพวกเรา เว็บ ดูหนังผ่านเน็ต หนังใหม่ ดูหนังผ่านอินเตอร์เน็ต 2023 Movie2k ต้องการที่จะให้ทุกคนได้ดูหนังผ่านเน็ตกันอย่างจุใจรวมทั้งคุ้มค่าที่จะดูที่สุด รวมทั้งทั้งผองที่บอกมา มันคือของแท้ ภาพคม ชัด ลึก เสียงเป๊ะ full HD ทุกเรื่องทุกตอน แถมเว็บไซต์ ดูหนังผ่านเน็ต หนังใหม่ ดูหนังผ่านอินเตอร์เน็ต 2023 ชองพวกเรา ยังอัพเดทหนังไวเยอะที่สุดในประเทศไทยอย่างไม่ต้องสงสัย เนื่องจากพวกเราจัดหนักจัดเต็มอีกทั้งหนังโรง หนังชนโรงพวกเราก็มี บางโอกาสมีหนังที่ยังไม่เข้าโรงที่เมืองไทยด้วย สุดจัดสุดจริง ดูหนังผ่านอินเตอร์เน็ต หนังใหม่ ดูหนังออนไลน์ 2023 กับพวกเรา movie2k จะมีผลให้ทุกคน ได้อัพเดทหนังก่อนคนใดกันแน่ ไม่ต้องมานั่งกลัวโดนสปอย เพราะเรา movie2k มีหนังให้ทุกคนได้ดูกันฟรีๆก่อนคนไหนกัน ดูหนังออนไลน์ หนังใหม่ ดูหนังออนไลน์ 2023 จำเป็นต้องนึกถึงเรา movie2k! ดูหนังหนังออนไลน์ 3.ดูหนังออนไลน์ดูหนังผ่านเน็ต กับเรา มีพวกรวมทั้งวัสดุค้นหาหนังที่ทันสมัยที่สุด เพื่อให้ลูกค้าทุกคน สามารถตามหาหนังที่อยากมองได้ หมู่พวกเรามิได้ใช้ AI สำหรับในการจัด เรา movie2k รู้เรื่องว่าการเข้าหมวดนึงแล้วมีหนังของอีกพวกนึงอยู่มันน่ารำคาญมากแค่ไหน พวกเราก็เลยจะต้องกระทำแยกเป็นชนิดและประเภทด้วยตัวเองอยู่ตลอดเวลามีหนังใหม่เข้ามา แถมอีกอย่างคือ อุปกรณ์ค้นหาของพวกเรา เป็นระบบค้นหาที่ล้ำยุคที่สุด ทุกท่านสามารถพิมคีย์เวิร์ดของหนังที่ทุกคนอยากจะมองได้เลย แล้วมันจะสร้างหมู่ที่มีความคล้ายคลึงกับคีย์เวิร์ดที่ทุกท่านเขียนลงไป บอกเลย เว็บไซต์อื่นค้นหาอะไรไม่เคยจะเจอ เพราะเหตุว่ามันเป็นตัวค้นหาแบบเก่าไงเล่า!
3.ดูหนังออนไลน์ดูหนังผ่านเน็ต กับเรา มีพวกรวมทั้งวัสดุค้นหาหนังที่ทันสมัยที่สุด เพื่อให้ลูกค้าทุกคน สามารถตามหาหนังที่อยากมองได้ หมู่พวกเรามิได้ใช้ AI สำหรับในการจัด เรา movie2k รู้เรื่องว่าการเข้าหมวดนึงแล้วมีหนังของอีกพวกนึงอยู่มันน่ารำคาญมากแค่ไหน พวกเราก็เลยจะต้องกระทำแยกเป็นชนิดและประเภทด้วยตัวเองอยู่ตลอดเวลามีหนังใหม่เข้ามา แถมอีกอย่างคือ อุปกรณ์ค้นหาของพวกเรา เป็นระบบค้นหาที่ล้ำยุคที่สุด ทุกท่านสามารถพิมคีย์เวิร์ดของหนังที่ทุกคนอยากจะมองได้เลย แล้วมันจะสร้างหมู่ที่มีความคล้ายคลึงกับคีย์เวิร์ดที่ทุกท่านเขียนลงไป บอกเลย เว็บไซต์อื่นค้นหาอะไรไม่เคยจะเจอ เพราะเหตุว่ามันเป็นตัวค้นหาแบบเก่าไงเล่า!
 ขอขอบพระคุณเว็ปไซต์
ขอขอบพระคุณเว็ปไซต์ 


 ทดสอบเล่นpg ทดสอบวันนี้แถมฟรีแจ็คพ็อตดีๆที่บางทีอาจแตกให้ท่านเป็นคนมั่งมีรายต่อไป
ทดสอบเล่นpg ทดสอบวันนี้แถมฟรีแจ็คพ็อตดีๆที่บางทีอาจแตกให้ท่านเป็นคนมั่งมีรายต่อไป เว็บตรง100% ทดลองเล่นสล็อต pg losdioses.info 9 สิงหา 23 Violette casino online
เว็บตรง100% ทดลองเล่นสล็อต pg losdioses.info 9 สิงหา 23 Violette casino online 
 เว็บไซต์สล็อตเว็บไซต์ตรงน้องใหม่ไฟแรง แฟน pg slot ไม่สมควรพลาด!
เว็บไซต์สล็อตเว็บไซต์ตรงน้องใหม่ไฟแรง แฟน pg slot ไม่สมควรพลาด! pg slot เว็บไซต์ตรงที่โปรโมชั่นและก็กิจกรรมแน่นสุดๆจะมีอะไรบ้าง มาดูกัน!
pg slot เว็บไซต์ตรงที่โปรโมชั่นและก็กิจกรรมแน่นสุดๆจะมีอะไรบ้าง มาดูกัน!
 ระบบ ทดสอบเล่นpg ของพวกเรามีดียังไงบ้าง?
ระบบ ทดสอบเล่นpg ของพวกเรามีดียังไงบ้าง? ประโยชน์ที่ได้รับมาจากการ ทดลองเล่นสล็อต pg คืออะไร?
ประโยชน์ที่ได้รับมาจากการ ทดลองเล่นสล็อต pg คืออะไร?
 สำหรับ leetgamers ทางเข้า pg ของเราเป็น pg slot เว็บไซต์ตรง ที่ได้รับการรับรองจากค่ายเกมสล็อตออนไลน์อย่าง pg slot เป็นระเบียบแล้วครับ คุณจะสามารถเล่นสล็อตออนไลน์กับพวกเราได้อย่างมีความสุขและไม่เป็นอันตรายแน่นอน ทางเข้า pg ของเราก็หาได้ง่าย แล้วก็ที่สำคัญกว่านั้นก็เป็น โปรโมชั่นของพวกเรานั้นจะต้องบอกเลยว่า จัดเต็มแบบสุดๆประทับใจแฟนคลับของ pg แน่นอนครับ ซึ่งจะมีโปรโมชั่นอะไรบ้างนั้น วันนี้ผมจะพาทุกคนมาดูกันเองครับ เลทโก!
สำหรับ leetgamers ทางเข้า pg ของเราเป็น pg slot เว็บไซต์ตรง ที่ได้รับการรับรองจากค่ายเกมสล็อตออนไลน์อย่าง pg slot เป็นระเบียบแล้วครับ คุณจะสามารถเล่นสล็อตออนไลน์กับพวกเราได้อย่างมีความสุขและไม่เป็นอันตรายแน่นอน ทางเข้า pg ของเราก็หาได้ง่าย แล้วก็ที่สำคัญกว่านั้นก็เป็น โปรโมชั่นของพวกเรานั้นจะต้องบอกเลยว่า จัดเต็มแบบสุดๆประทับใจแฟนคลับของ pg แน่นอนครับ ซึ่งจะมีโปรโมชั่นอะไรบ้างนั้น วันนี้ผมจะพาทุกคนมาดูกันเองครับ เลทโก! 4. โปรโมชั่นสายทุนน้อยมาทางนี้ ทางเข้า pg
4. โปรโมชั่นสายทุนน้อยมาทางนี้ ทางเข้า pg

 ผู้เล่นสามารถซื้อได้ง่าย สบายรวดเร็วทันใจ รวมทั้งที่สำคัญสำเร็จทดแทนที่สูง เพราะเป็นการซื้อโดยไม่ผ่านคนกลางเมื่อถูกรางวัลก็สามารถรับเงินเต็มจำนวนแล้วก็ได้รับเงินอย่างรวดเร็ว ไม่ต้องรอคอยเสมือนซื้อหวยตามบ้านเรา เมื่อถูกรางวัลแล้วยังมิได้รับเงินในวันนี้ จะต้องรับเงินอีกครั้งในวันต่อไปหรือแม้มีผู้เล่นถูกรางวัลมากมายๆหลายๆคนก็ทำให้การชำระเงินล่าช้าไปอีก
ผู้เล่นสามารถซื้อได้ง่าย สบายรวดเร็วทันใจ รวมทั้งที่สำคัญสำเร็จทดแทนที่สูง เพราะเป็นการซื้อโดยไม่ผ่านคนกลางเมื่อถูกรางวัลก็สามารถรับเงินเต็มจำนวนแล้วก็ได้รับเงินอย่างรวดเร็ว ไม่ต้องรอคอยเสมือนซื้อหวยตามบ้านเรา เมื่อถูกรางวัลแล้วยังมิได้รับเงินในวันนี้ จะต้องรับเงินอีกครั้งในวันต่อไปหรือแม้มีผู้เล่นถูกรางวัลมากมายๆหลายๆคนก็ทำให้การชำระเงินล่าช้าไปอีก หวยพม่า แทงหวยสด Game.no1huay.com 22 July 23 Lyndon จ่ายสูงที่สุด แทงหวยสดขอ-เลข-เด็ด 3 ตัว-ตรง Top 9
หวยพม่า แทงหวยสด Game.no1huay.com 22 July 23 Lyndon จ่ายสูงที่สุด แทงหวยสดขอ-เลข-เด็ด 3 ตัว-ตรง Top 9 ขอขอบคุณมากเว็ปไซต์
ขอขอบคุณมากเว็ปไซต์  Jubyet69 ขอตอบคำถามที่ตรงนี้เลยว่าหนังโป๊69 ทำไมในตอนนี้ การ ดูหนังx ออนไลน์หรือ หนังเอ็กซ์69 ถึงเป็นที่ฮ็อตฮิตเป็นอันมากแล้วก็แพร่หลาย ตามจริงแล้ว มันเป็นเพราะเหตุว่า สถิติประชากรคนภายในประเทศไทย ช่วงอายุวัยยุ่งถึงวัยทำงานตอนแรกนั้นมีความต้องการทางเพศสูงเป็นอย่างมาก และก็จากข้อมูลสถิติเพิ่ม ที่ยังน่าตกใจกว่าก็คือ คนภายในตอนวัยระหว่างนี้ จะมีคู่ที่สามารถมีกิจกรรมทางเพศหรือมีแฟนแค่เพียง 50% เพียงแค่นั้น นั่นคงเป็นเหตุผลที่ว่า เพราะเหตุไรเว็บไซต์ ดูหนังx ถึงเป็นที่ต้องการในสังคมปัจจุบัน ด้วยเหตุว่าความต้องการทางเพศรวมทั้งอารมณ์ของพวกเขามันจำเป็นต้องได้รับการปลดปล่อยนั่นเอง นอกเหนือจากนี้ การตอบสนองความต้องการทางเพศโดยการ ดูหนังx หนังเอ็กซ์69 หนัง69 และก็ หนัง 18 ฟรี ทำให้มีการเกิดการช่วยตนเองของผู้ชาย ทำให้ช่วยลดความเครียดและก็ลดเปอร์เซ็นต์การเป็นโรคเกี่ยวต่อมลูกหมากอีกด้วย และก็ในส่วนของสาวๆการช่วยตนเองจะช่วยผ่อนคลายความเครียดเช่นเดียวกัน แล้วก็ยังสามารช่วยบรรเทาอาการไม่ดีเหมือนปกติจากระดูได้อีกด้วย นอกจากนั้นยังมีเรื่องมีราวของการข่มขืนกระทำชำเราในคดีต่างๆการ ดูหนังx เพื่อช่วยเหลือตัวเองนั้น ช่วยลดความรู้สึกทางเพศลงทำให้ ลดอัตราการเกิดคดีที่เกี่ยวกับการคุกคามทางเพศอีกด้วย นี่เป็นข้อสรุปจากประเทศ ประเทศญี่ปุ่นเลยคะ คิคิ รวมทั้งด้วยเหตุผลทั้งสิ้นนี้ Jubyet69 หนัง 18 ฟรีเลยอยากให้ทุกคนได้แฮปปี้กับเวลาของตนเอง เวลาผักผ่อนหย่อนยานคลายในที่ลับที่ไม่มีใครมองเห็น หรือจะให้ Jubyet69 รอเป็นเพื่อนแก้เหงาในวันที่เปล่าเปลี่ยวหัวใจก็ได้น้า
Jubyet69 ขอตอบคำถามที่ตรงนี้เลยว่าหนังโป๊69 ทำไมในตอนนี้ การ ดูหนังx ออนไลน์หรือ หนังเอ็กซ์69 ถึงเป็นที่ฮ็อตฮิตเป็นอันมากแล้วก็แพร่หลาย ตามจริงแล้ว มันเป็นเพราะเหตุว่า สถิติประชากรคนภายในประเทศไทย ช่วงอายุวัยยุ่งถึงวัยทำงานตอนแรกนั้นมีความต้องการทางเพศสูงเป็นอย่างมาก และก็จากข้อมูลสถิติเพิ่ม ที่ยังน่าตกใจกว่าก็คือ คนภายในตอนวัยระหว่างนี้ จะมีคู่ที่สามารถมีกิจกรรมทางเพศหรือมีแฟนแค่เพียง 50% เพียงแค่นั้น นั่นคงเป็นเหตุผลที่ว่า เพราะเหตุไรเว็บไซต์ ดูหนังx ถึงเป็นที่ต้องการในสังคมปัจจุบัน ด้วยเหตุว่าความต้องการทางเพศรวมทั้งอารมณ์ของพวกเขามันจำเป็นต้องได้รับการปลดปล่อยนั่นเอง นอกเหนือจากนี้ การตอบสนองความต้องการทางเพศโดยการ ดูหนังx หนังเอ็กซ์69 หนัง69 และก็ หนัง 18 ฟรี ทำให้มีการเกิดการช่วยตนเองของผู้ชาย ทำให้ช่วยลดความเครียดและก็ลดเปอร์เซ็นต์การเป็นโรคเกี่ยวต่อมลูกหมากอีกด้วย และก็ในส่วนของสาวๆการช่วยตนเองจะช่วยผ่อนคลายความเครียดเช่นเดียวกัน แล้วก็ยังสามารช่วยบรรเทาอาการไม่ดีเหมือนปกติจากระดูได้อีกด้วย นอกจากนั้นยังมีเรื่องมีราวของการข่มขืนกระทำชำเราในคดีต่างๆการ ดูหนังx เพื่อช่วยเหลือตัวเองนั้น ช่วยลดความรู้สึกทางเพศลงทำให้ ลดอัตราการเกิดคดีที่เกี่ยวกับการคุกคามทางเพศอีกด้วย นี่เป็นข้อสรุปจากประเทศ ประเทศญี่ปุ่นเลยคะ คิคิ รวมทั้งด้วยเหตุผลทั้งสิ้นนี้ Jubyet69 หนัง 18 ฟรีเลยอยากให้ทุกคนได้แฮปปี้กับเวลาของตนเอง เวลาผักผ่อนหย่อนยานคลายในที่ลับที่ไม่มีใครมองเห็น หรือจะให้ Jubyet69 รอเป็นเพื่อนแก้เหงาในวันที่เปล่าเปลี่ยวหัวใจก็ได้น้า

 Casinoruby88 สล็อตออนไลน์ เป็นอย่างไร เป็นใครกันแน่มาจากไหน มาทำความรู้จักกันหน่อยดีมากยิ่งกว่าจ้า
Casinoruby88 สล็อตออนไลน์ เป็นอย่างไร เป็นใครกันแน่มาจากไหน มาทำความรู้จักกันหน่อยดีมากยิ่งกว่าจ้า เพราะเหตุไร Casinoruby88 pgslot ถึงน่าเล่น มีข้อดีอะไรที่แตกต่างจาก สล็อตเว็บตรง อื่นๆเพราะอะไร Casinoruby88 ถึงเป็น สล็อตแตกหนัก ที่ยืนหนึ่งอยู่ในแวดวง สล็อตออนไลน์ มาอย่างยาวนาน?
เพราะเหตุไร Casinoruby88 pgslot ถึงน่าเล่น มีข้อดีอะไรที่แตกต่างจาก สล็อตเว็บตรง อื่นๆเพราะอะไร Casinoruby88 ถึงเป็น สล็อตแตกหนัก ที่ยืนหนึ่งอยู่ในแวดวง สล็อตออนไลน์ มาอย่างยาวนาน? แจกสูตรสล็อต สล็อตพีจี https://Casinoruby88.com 29 Apr 23 Alphonse คาสิโน pgสล็อตมีผู้เชี่ยวชาญ Top 82
แจกสูตรสล็อต สล็อตพีจี https://Casinoruby88.com 29 Apr 23 Alphonse คาสิโน pgสล็อตมีผู้เชี่ยวชาญ Top 82
 เพราะเหตุใดควรดูหนังออนไลน์กับเรา Moviekece.com
เพราะเหตุใดควรดูหนังออนไลน์กับเรา Moviekece.com


 วิธีเล่นสล็อตครั้งแรก เล่นแบบไหนให้โบนัสแตก แบบไม่ต้องขอคืนดีดวง วันนี้ เว็บไซต์มาแรง ที่และประสิทธิภาพสล็อตpg จะพาคุณไปตรวจสอบกรรมวิธีการเล่นฉบับมือใหม่ เป็นเทคนิคการเล่นที่เข้าใจง่าย ทำเงินได้จริง คุณจะสนุกกับการเดิมพันได้ไม่ติด ไม่ว่าจะเล่นผ่านวัสดุอุปกรณ์ไหน พวกเราพร้อมจ่ายรางวัลเต็มไม่หัก ไม่มีการล็อคผลชนะ PGSLOT เว็บไซต์เดิมพันครบวงจร พร้อมเปิดให้เข้ามาสนุกสนานกับการเดิมพันผ่านมือถือ สัมผัสความครบครันของบริการ ที่จะเปลี่ยนแปลงให้คุณเป็นลูกค้า VIP เข้าถึงเกมสล็อตสุดพรีเมี่ยวได้ทุกวี่ทุกวัน
วิธีเล่นสล็อตครั้งแรก เล่นแบบไหนให้โบนัสแตก แบบไม่ต้องขอคืนดีดวง วันนี้ เว็บไซต์มาแรง ที่และประสิทธิภาพสล็อตpg จะพาคุณไปตรวจสอบกรรมวิธีการเล่นฉบับมือใหม่ เป็นเทคนิคการเล่นที่เข้าใจง่าย ทำเงินได้จริง คุณจะสนุกกับการเดิมพันได้ไม่ติด ไม่ว่าจะเล่นผ่านวัสดุอุปกรณ์ไหน พวกเราพร้อมจ่ายรางวัลเต็มไม่หัก ไม่มีการล็อคผลชนะ PGSLOT เว็บไซต์เดิมพันครบวงจร พร้อมเปิดให้เข้ามาสนุกสนานกับการเดิมพันผ่านมือถือ สัมผัสความครบครันของบริการ ที่จะเปลี่ยนแปลงให้คุณเป็นลูกค้า VIP เข้าถึงเกมสล็อตสุดพรีเมี่ยวได้ทุกวี่ทุกวัน วิธีเล่นสล็อตให้แตก อัปเดตพอดีเว็บไซต์ PGSLOT ทุกวี่วัน
วิธีเล่นสล็อตให้แตก อัปเดตพอดีเว็บไซต์ PGSLOT ทุกวี่วัน




 เว็บดูหนังออนไลน์มาใหม่ปัจจุบัน movieskub
เว็บดูหนังออนไลน์มาใหม่ปัจจุบัน movieskub 

 สล็อตpg ทดลองเล่นสล็อต ทดลองเล่นpg กับ freeslot168 เว็บสล็อตของแท้ตัวตึงระดับสากล
สล็อตpg ทดลองเล่นสล็อต ทดลองเล่นpg กับ freeslot168 เว็บสล็อตของแท้ตัวตึงระดับสากล เพราะเหตุใดพวกเราถึงเป็นตัวท็อปของ ทดลองเล่นสล็อต นี่บางทีก็อาจจะเป็นปริศนาที่ดี หากคุณไม่รู้จักจะพวกเรามาก่อน เพราะเหตุว่าในแวดวง สล็อตออนไลน์ ทุกภาคส่วนทราบ ว่า สล็อตpg เป็นตังเต็งสุดยอดเกี่ยวกับการเดิมสล็อตออนไลน์ สล็อตpg ยืนหนึ่งมาเสมอ สล็อตpg ทดลองเล่นสล็อต ทดลองเล่นpg ที่ได้มาตรฐานที่สุดมันแน่ๆว่าควรจะเป็นพวกเรา เพราะพวกเราเป็นสายตรงจาก Pg soft ค่ายสล็อต ลำดับต้นๆของเอเชียแปซิฟิก ด้วยระบบปฏิบัติการที่นำสมัย เข้าถึงทุกคน เล่นง่าย แตกหนัก จ่ายจริง เพียงแค่ชื่อเว็บไซต์ก็รู้แล้ว ว่าเรานี่แหละ เป็นตัวจริงของ สล็อตpg ทดสอบเล่นสล็อต ทดลองเล่นpg ค่ายสล็อตที่ทุกคนต่างใฝ่ฝัน freeslot168 จัดให้จ้า
เพราะเหตุใดพวกเราถึงเป็นตัวท็อปของ ทดลองเล่นสล็อต นี่บางทีก็อาจจะเป็นปริศนาที่ดี หากคุณไม่รู้จักจะพวกเรามาก่อน เพราะเหตุว่าในแวดวง สล็อตออนไลน์ ทุกภาคส่วนทราบ ว่า สล็อตpg เป็นตังเต็งสุดยอดเกี่ยวกับการเดิมสล็อตออนไลน์ สล็อตpg ยืนหนึ่งมาเสมอ สล็อตpg ทดลองเล่นสล็อต ทดลองเล่นpg ที่ได้มาตรฐานที่สุดมันแน่ๆว่าควรจะเป็นพวกเรา เพราะพวกเราเป็นสายตรงจาก Pg soft ค่ายสล็อต ลำดับต้นๆของเอเชียแปซิฟิก ด้วยระบบปฏิบัติการที่นำสมัย เข้าถึงทุกคน เล่นง่าย แตกหนัก จ่ายจริง เพียงแค่ชื่อเว็บไซต์ก็รู้แล้ว ว่าเรานี่แหละ เป็นตัวจริงของ สล็อตpg ทดสอบเล่นสล็อต ทดลองเล่นpg ค่ายสล็อตที่ทุกคนต่างใฝ่ฝัน freeslot168 จัดให้จ้า เหตุผลสำคัญๆที่ สล็อตเว็บไซต์ตรง888 พึ่งเปิดให้บริการ สล็อต55 55slot เวลานี้ก็เพราะเหตุว่า พวกเรา
เหตุผลสำคัญๆที่ สล็อตเว็บไซต์ตรง888 พึ่งเปิดให้บริการ สล็อต55 55slot เวลานี้ก็เพราะเหตุว่า พวกเรา  joker123 สล็อตเว็บตรงแตกง่าย รับประกันความแตกง่ายทุกเกม บอกเลยนะขอรับว่า ทุกวันนี้ หากใครยังคงเล่นสล็อตเว็บเอเย่นต์อยู่ล่ะก็ เชยสลัดเลยจ้ะครับ! ในช่วงเวลานี้ใครๆก็เล่นสล็อตเว็บไซต์ตรงกันทั้งนั้นแล้ว ยิ่งเป็นสล็อตเว็บไซต์ตรงของโจ๊กเกอร์123ด้วยแล้ว ความสนุกสนานแล้วก็ความรวยสองเท่าเลยล่ะครับผม! ด้วยเหตุว่าพวกเราเป็นสล็อตเว็บตรงแตกง่าย การันตีความแตกง่ายทุกเกมของ joker123 กันไปเลย ซึ่งเกมจากค่าย
joker123 สล็อตเว็บตรงแตกง่าย รับประกันความแตกง่ายทุกเกม บอกเลยนะขอรับว่า ทุกวันนี้ หากใครยังคงเล่นสล็อตเว็บเอเย่นต์อยู่ล่ะก็ เชยสลัดเลยจ้ะครับ! ในช่วงเวลานี้ใครๆก็เล่นสล็อตเว็บไซต์ตรงกันทั้งนั้นแล้ว ยิ่งเป็นสล็อตเว็บไซต์ตรงของโจ๊กเกอร์123ด้วยแล้ว ความสนุกสนานแล้วก็ความรวยสองเท่าเลยล่ะครับผม! ด้วยเหตุว่าพวกเราเป็นสล็อตเว็บตรงแตกง่าย การันตีความแตกง่ายทุกเกมของ joker123 กันไปเลย ซึ่งเกมจากค่าย


 คนไม่ใช่น้อยอาจจะเคยตั้งเรื่องที่น่าสงสัยกับตัวเองแบบเดียวกันว่า การฝากแบบรับโบนัสเครดิตฟรีกับการฝากแบบไม่รับโบนัสเครดิตฟรีมันแตกต่างกันอย่างไร แล้วแบบไหนมันดีกว่ากัน ผมจะอธิบายให้ฟังแบบโดยประมาณเลยค่ะครับ การฝากแบบรับโบนัสเครดิตฟรีเป็นการที่คุณฝากเงินเข้ามาแล้วรับโปรโมชั่นโบนัสเครดิตฟรีต่างๆซึ่งโดยมากแล้ว โปรโมชั่นโบนัสเครดิตฟรีจะมีเงื่อนไขในส่วนของกระบวนการทำยอดให้ได้ตามที่ได้มีการกำหนดเท่านั้น ถึงจะสามารถถอนเงินได้ตามที่มีการกำหนดเหมือนกัน ผู้คนจำนวนมากก็บางครั้งอาจจะชอบที่กำลังจะได้รับโบนัสเครดิตฟรีเพิ่ม มันก็อย่างกับการที่เรามีทุนเพิ่มขึ้นมานั่นล่ะขอรับ แม้จะจะต้องทำยอด แต่ว่าปกติก็ไม่มีใครเล่น joker123 แล้วอยากผลกำไรเพียงแค่ 1 เท่าหรอกจริงไหมขอรับ โดยเหตุนั้น กระบวนการทำยอด 2 หรือ 3 เท่า มันก็ดังการเล่นปกติ
คนไม่ใช่น้อยอาจจะเคยตั้งเรื่องที่น่าสงสัยกับตัวเองแบบเดียวกันว่า การฝากแบบรับโบนัสเครดิตฟรีกับการฝากแบบไม่รับโบนัสเครดิตฟรีมันแตกต่างกันอย่างไร แล้วแบบไหนมันดีกว่ากัน ผมจะอธิบายให้ฟังแบบโดยประมาณเลยค่ะครับ การฝากแบบรับโบนัสเครดิตฟรีเป็นการที่คุณฝากเงินเข้ามาแล้วรับโปรโมชั่นโบนัสเครดิตฟรีต่างๆซึ่งโดยมากแล้ว โปรโมชั่นโบนัสเครดิตฟรีจะมีเงื่อนไขในส่วนของกระบวนการทำยอดให้ได้ตามที่ได้มีการกำหนดเท่านั้น ถึงจะสามารถถอนเงินได้ตามที่มีการกำหนดเหมือนกัน ผู้คนจำนวนมากก็บางครั้งอาจจะชอบที่กำลังจะได้รับโบนัสเครดิตฟรีเพิ่ม มันก็อย่างกับการที่เรามีทุนเพิ่มขึ้นมานั่นล่ะขอรับ แม้จะจะต้องทำยอด แต่ว่าปกติก็ไม่มีใครเล่น joker123 แล้วอยากผลกำไรเพียงแค่ 1 เท่าหรอกจริงไหมขอรับ โดยเหตุนั้น กระบวนการทำยอด 2 หรือ 3 เท่า มันก็ดังการเล่นปกติ
 สำหรับ มหาวิทยาลัยราชภัฏ สวนสุนันทา นับว่าเป็นอีกหนึ่งมหาวิทยาลัยของรัฐ ที่ตั้งอยู่ภายในเขตพื้นที่ของวังสวนสุนันทา ที่เป็นเขตของพระราชฐานของพระราชสำนักดุสิต ในยุครัชกาลที่ 5 มาก่อน โดยที่มีพื้นฐานมาจากการเริ่มต้นด้วย การเป็นสถานที่เรียนฝึกอาจารย์ประถมหญิง ที่แรกของเมืองไทย แล้วคุณรู้หรือเปล่าว่าที่แห่งนี้ ยังเต็มไปด้วยความเชื่อถือและก็เรื่องเล่าต่างๆจากรุ่นพี่สู่รุ่นน้องมากมายนานาประการเรื่อง อย่างยิ่งจริงๆจนกระทั่งเป็นขนบธรรมเนียม ขนบธรรมเนียมในมหาวิทยาลัย ราชภัฏ สวนสุนันทาแล้ว ซึ่งมีเรื่องมีราวอะไรที่น่าสนใจบ้างเราไปดูกันดีกว่า
สำหรับ มหาวิทยาลัยราชภัฏ สวนสุนันทา นับว่าเป็นอีกหนึ่งมหาวิทยาลัยของรัฐ ที่ตั้งอยู่ภายในเขตพื้นที่ของวังสวนสุนันทา ที่เป็นเขตของพระราชฐานของพระราชสำนักดุสิต ในยุครัชกาลที่ 5 มาก่อน โดยที่มีพื้นฐานมาจากการเริ่มต้นด้วย การเป็นสถานที่เรียนฝึกอาจารย์ประถมหญิง ที่แรกของเมืองไทย แล้วคุณรู้หรือเปล่าว่าที่แห่งนี้ ยังเต็มไปด้วยความเชื่อถือและก็เรื่องเล่าต่างๆจากรุ่นพี่สู่รุ่นน้องมากมายนานาประการเรื่อง อย่างยิ่งจริงๆจนกระทั่งเป็นขนบธรรมเนียม ขนบธรรมเนียมในมหาวิทยาลัย ราชภัฏ สวนสุนันทาแล้ว ซึ่งมีเรื่องมีราวอะไรที่น่าสนใจบ้างเราไปดูกันดีกว่า สำหรับเด็กจากวิทยาลัยนานาประเทศ เป็นเด็กที่ค่อนข้างไม่เหมือนกัน จากภาคธรรมดาทุกๆสิ่งทุกๆอย่างที่มองมีออร่า แล้วก็เห็นได้อย่างชัดเจนถึงความไม่เหมือน ราชภัฏ หรือรวมถึงการไหว้พระนาง ต้องไหว้ด้วยกุหลาบสีชมพู และถวายก่อน 11 โมงรุ่งเช้าเท่านั้น เพื่อเป็นสิริมงคล
สำหรับเด็กจากวิทยาลัยนานาประเทศ เป็นเด็กที่ค่อนข้างไม่เหมือนกัน จากภาคธรรมดาทุกๆสิ่งทุกๆอย่างที่มองมีออร่า แล้วก็เห็นได้อย่างชัดเจนถึงความไม่เหมือน ราชภัฏ หรือรวมถึงการไหว้พระนาง ต้องไหว้ด้วยกุหลาบสีชมพู และถวายก่อน 11 โมงรุ่งเช้าเท่านั้น เพื่อเป็นสิริมงคล
.png) เรื่องน่าสนใจ หลังรั้ว
เรื่องน่าสนใจ หลังรั้ว  สำหรับเสื้อของนักศึกษาประถมแสดง ที่จะมีการปักจุด โดยสีแดงซึ่งก็คือผู้ดูแลมารับที่โรงเรียนสีเขียวเป็นกลับบ้านเอง ที่จะแบ่งให้มองเห็นกันไปชัดแจ้งเลยว่า เด็กกลุ่มนี้นั้นสามารถที่จะแยกได้ อย่างชัดเจนอีกด้วย
สำหรับเสื้อของนักศึกษาประถมแสดง ที่จะมีการปักจุด โดยสีแดงซึ่งก็คือผู้ดูแลมารับที่โรงเรียนสีเขียวเป็นกลับบ้านเอง ที่จะแบ่งให้มองเห็นกันไปชัดแจ้งเลยว่า เด็กกลุ่มนี้นั้นสามารถที่จะแยกได้ อย่างชัดเจนอีกด้วย




 ผลรวมเลขทะเบียนรถมงคลขายทะเบียนรถ เจ้าของขายเอง ทะเบียนรถสวย Tabiengod.com 23 มีนา 24 Niki จองทะเบียนรถ ต่างจังหวัดเช็คเลขทะเบียนรถมงคล ขายทะเบียนรถจองทะเบียนรถ Top 85
ผลรวมเลขทะเบียนรถมงคลขายทะเบียนรถ เจ้าของขายเอง ทะเบียนรถสวย Tabiengod.com 23 มีนา 24 Niki จองทะเบียนรถ ต่างจังหวัดเช็คเลขทะเบียนรถมงคล ขายทะเบียนรถจองทะเบียนรถ Top 85 • ฟีพบร์ต่างๆของเกม เกม สล็อต pg ในตอนนี้ ถ้าเกิดไม่นับเกมแบบคลาสิกล่ะก็ เกมสมัยใหม่หรือที่พวกเราเรียกกันว่า เกมสล็อตแบบวีดิโอ เกือบจะเป็นเกมที่ผสมฟีพบร์ต่างๆมากอยู่แล้วครับ ซึ่งคุณสามารถอ่านทำความเข้าใจเกี่ยวกับฟีเจอร์ต่างๆได้เลยครับ ด้วยเหตุว่ามันส่งผลต่อการเล่นเกมสล็อตออนไลน์อย่างมาก ฟีเจอร์ต่างๆจะช่วยทำให้คุณเข้าถึงแจ็กพอตของเกมได้ง่ายเพิ่มขึ้น ยิ่งมีฟีพบร์มากแค่ไหน ก็ยิ่งมีโอกาสอย่างมากเพียงแค่นั้นนั่นเองครับผม
• ฟีพบร์ต่างๆของเกม เกม สล็อต pg ในตอนนี้ ถ้าเกิดไม่นับเกมแบบคลาสิกล่ะก็ เกมสมัยใหม่หรือที่พวกเราเรียกกันว่า เกมสล็อตแบบวีดิโอ เกือบจะเป็นเกมที่ผสมฟีพบร์ต่างๆมากอยู่แล้วครับ ซึ่งคุณสามารถอ่านทำความเข้าใจเกี่ยวกับฟีเจอร์ต่างๆได้เลยครับ ด้วยเหตุว่ามันส่งผลต่อการเล่นเกมสล็อตออนไลน์อย่างมาก ฟีเจอร์ต่างๆจะช่วยทำให้คุณเข้าถึงแจ็กพอตของเกมได้ง่ายเพิ่มขึ้น ยิ่งมีฟีพบร์มากแค่ไหน ก็ยิ่งมีโอกาสอย่างมากเพียงแค่นั้นนั่นเองครับผม ชี้แนะเกมสล็อตออนไลน์จากค่าย pgslot กับเกมที่มีชื่อว่า Farm Invaders
ชี้แนะเกมสล็อตออนไลน์จากค่าย pgslot กับเกมที่มีชื่อว่า Farm Invaders เกมPG pgslot pgslot.gd 1 February Nichol โอนไว slotแจกโบนัสทุกซีซั่น Top 75
เกมPG pgslot pgslot.gd 1 February Nichol โอนไว slotแจกโบนัสทุกซีซั่น Top 75


 1.บริการทำ Landing Page ถ้าคุณปรารถนาสร้าง Landinf Page สำหรับทำการตลาดแบบ SEO รับทำเว็บพนัน คุณก็สามารถมาใช้บริการกับพวกเราได้เลยครับ เพื่อเพิ่มหนทางในการเข้าถึงของกลุ่มลูกค้าก้าวหน้าขึ้น มี Template ให้คุณเลือกใช้ได้ฟรี โดยมีค่าบริการ 5,000 บาทต่อเดือน แล้วก็ค่าทำ 10,000 บาท
1.บริการทำ Landing Page ถ้าคุณปรารถนาสร้าง Landinf Page สำหรับทำการตลาดแบบ SEO รับทำเว็บพนัน คุณก็สามารถมาใช้บริการกับพวกเราได้เลยครับ เพื่อเพิ่มหนทางในการเข้าถึงของกลุ่มลูกค้าก้าวหน้าขึ้น มี Template ให้คุณเลือกใช้ได้ฟรี โดยมีค่าบริการ 5,000 บาทต่อเดือน แล้วก็ค่าทำ 10,000 บาท Standard Package นับว่าเป็นแพ็กเกจสำหรับคนที่ต้องการเปิดเว็บพนันแบบทำเป็นทันที เปิดเว็บไซต์ด้วยระบบออโต้จาก HYPERX เปิดเว็บพนัน รับประกันความชอบใจแน่นอนนะครับ โดยมีเนื้อหาต่าง ดังต่อไปนี้
Standard Package นับว่าเป็นแพ็กเกจสำหรับคนที่ต้องการเปิดเว็บพนันแบบทำเป็นทันที เปิดเว็บไซต์ด้วยระบบออโต้จาก HYPERX เปิดเว็บพนัน รับประกันความชอบใจแน่นอนนะครับ โดยมีเนื้อหาต่าง ดังต่อไปนี้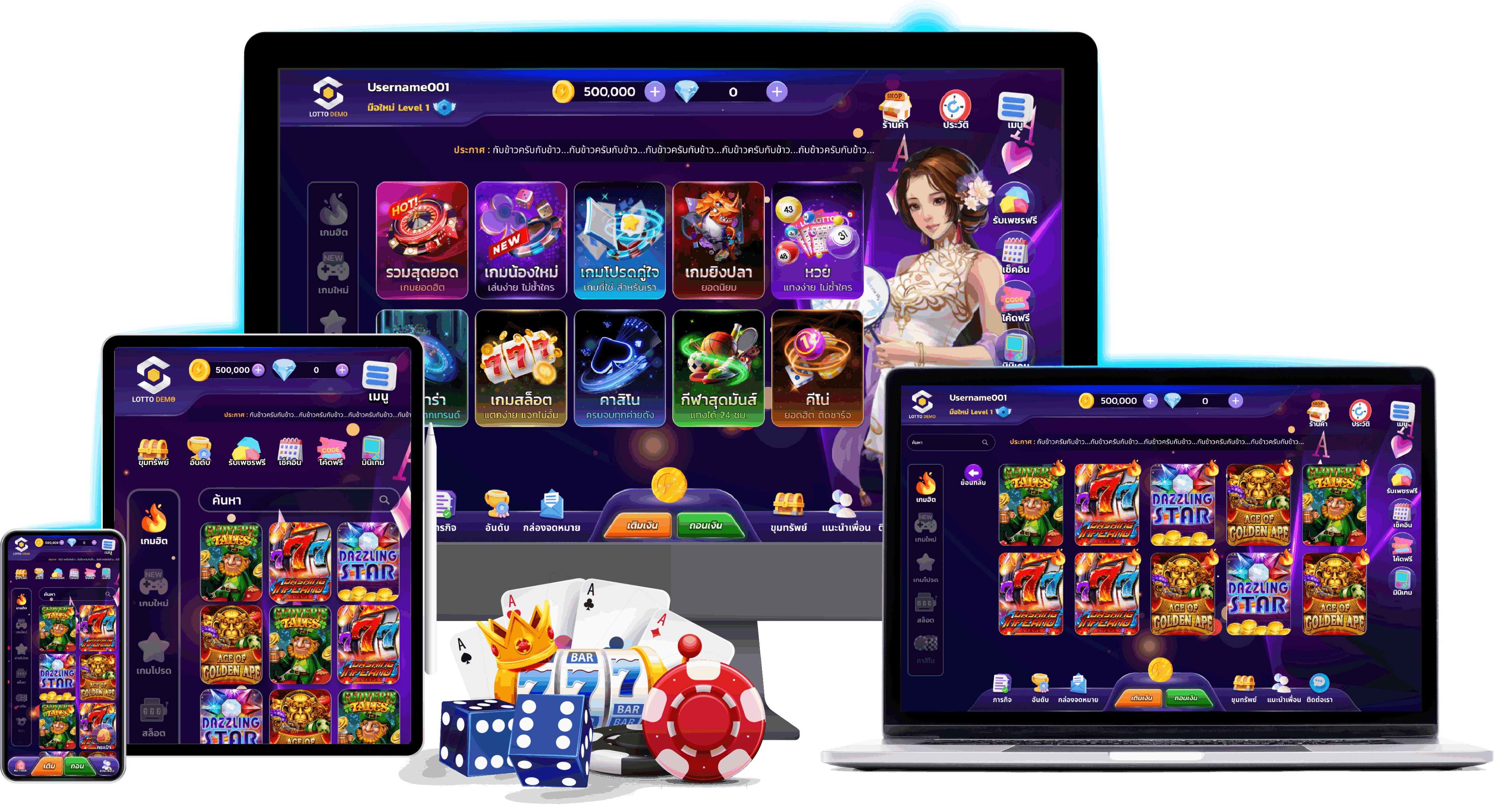 ระบบเว็บทันสมัย เปิดเว็บพนัน hyperxtech Hyperxtech.io 29 มีนาคม 2024 Orlando เข้ามาเช็คเครดิตก่อนได้ เปิดเว็บพนัน
ระบบเว็บทันสมัย เปิดเว็บพนัน hyperxtech Hyperxtech.io 29 มีนาคม 2024 Orlando เข้ามาเช็คเครดิตก่อนได้ เปิดเว็บพนัน  สล็อตเว็บตรง เกมออนไลน์ที่ได้รับความนิยม เล่นได้แบบมันส์ๆจัดเต็มไม่มีเบื่อที่ temmax69
สล็อตเว็บตรง เกมออนไลน์ที่ได้รับความนิยม เล่นได้แบบมันส์ๆจัดเต็มไม่มีเบื่อที่ temmax69 pgslot เป็นอย่างไรแล้วมันดีอย่างไร เพราะเหตุใดใครๆก็อยากเล่น
pgslot เป็นอย่างไรแล้วมันดีอย่างไร เพราะเหตุใดใครๆก็อยากเล่น
 • ถ้าเกิดยังคลุมเคลือ ไปทดลองหาเว็บ ทดสอบเล่นสล็อต ก่อนก็ยังได้ ในช่วงเวลานี้ตามสล็อตเว็บตรงต่างๆชอบมีระบบทดลองเล่นให้ ซึ่งในเว็บไซต์ตรง ระบบ ทดสอบเล่นสล็อตจะเป็นระบบที่มีอัตราการสุ่มการแตกเหมือนกับเกมจริงๆดังนั้น ถ้าเกิดยังไม่แน่ใจในเกมที่จะเล่น ให้ไปทดลองดูก่อน เผื่อจะได้รู้ว่าเกมไหนเข้ามือเกมไหนเราเสีย!
• ถ้าเกิดยังคลุมเคลือ ไปทดลองหาเว็บ ทดสอบเล่นสล็อต ก่อนก็ยังได้ ในช่วงเวลานี้ตามสล็อตเว็บตรงต่างๆชอบมีระบบทดลองเล่นให้ ซึ่งในเว็บไซต์ตรง ระบบ ทดสอบเล่นสล็อตจะเป็นระบบที่มีอัตราการสุ่มการแตกเหมือนกับเกมจริงๆดังนั้น ถ้าเกิดยังไม่แน่ใจในเกมที่จะเล่น ให้ไปทดลองดูก่อน เผื่อจะได้รู้ว่าเกมไหนเข้ามือเกมไหนเราเสีย!







 ทริคเด็ดเลือกเกม pgslot ให้แตกหนักได้โบนัสก้อนโต เข้าฟรีสปินง่ายรับเงินไว
ทริคเด็ดเลือกเกม pgslot ให้แตกหนักได้โบนัสก้อนโต เข้าฟรีสปินง่ายรับเงินไว slot เกมสล็อตแตกหนักมากยิ่งกว่า 200 เกม เล่นได้ไม่จำกัด บันเทิงใจได้ไม่อั้น
slot เกมสล็อตแตกหนักมากยิ่งกว่า 200 เกม เล่นได้ไม่จำกัด บันเทิงใจได้ไม่อั้น อย่างไรก็ตาม แต่ละเกมpgslot ของค่ายพีจีก็จะมีขณะที่แจกหนักแตกต่างกันออกไป โดยเหตุนี้ ก็เลยเป็นสิ่งจำเป็นที่แต่ละผู้เล่นจำเป็นที่จะต้องเลือกเกมที่สมควร เล่าเรียนกระบวนการเลือกเกมเพื่อคุณสามารถโกยผลกำไรจากการเดิมพันได้อย่างดีเยี่ยม ซึ่งปัจจัยสำหรับในการเลือกเกมก็มีอยู่หลายประเภท ไม่ว่าจะเป็นการไตร่ตรองภาพรวมของเกม อัตราการชำระเงิน ธีมเกมและอื่นๆที่หากคุณปรารถนาทำเงินจากการเล่นเกมเว็บตรงเปิดใหม่ สิ่งที่สำคัญคือการเรียนภาพรวมรากฐานเพื่อนำมาเลือกเกมที่เหมาะสมที่สุด ซึ่งค่ายเกมสล็อตพีจีจะมีการบอกเนื้อหาต่างๆไว้แบบครบถ้วน ทำให้คุณสามารถอ่านข้อมูลเพื่อประกอบกิจการพินิจได้ง่ายยิ่งกว่าเดิม
อย่างไรก็ตาม แต่ละเกมpgslot ของค่ายพีจีก็จะมีขณะที่แจกหนักแตกต่างกันออกไป โดยเหตุนี้ ก็เลยเป็นสิ่งจำเป็นที่แต่ละผู้เล่นจำเป็นที่จะต้องเลือกเกมที่สมควร เล่าเรียนกระบวนการเลือกเกมเพื่อคุณสามารถโกยผลกำไรจากการเดิมพันได้อย่างดีเยี่ยม ซึ่งปัจจัยสำหรับในการเลือกเกมก็มีอยู่หลายประเภท ไม่ว่าจะเป็นการไตร่ตรองภาพรวมของเกม อัตราการชำระเงิน ธีมเกมและอื่นๆที่หากคุณปรารถนาทำเงินจากการเล่นเกมเว็บตรงเปิดใหม่ สิ่งที่สำคัญคือการเรียนภาพรวมรากฐานเพื่อนำมาเลือกเกมที่เหมาะสมที่สุด ซึ่งค่ายเกมสล็อตพีจีจะมีการบอกเนื้อหาต่างๆไว้แบบครบถ้วน ทำให้คุณสามารถอ่านข้อมูลเพื่อประกอบกิจการพินิจได้ง่ายยิ่งกว่าเดิม
 Slotpg ที่สุดของเว็บไซต์สล็อตออนไลน์ไม่ผ่านเอเย่นต์ การันตีหน้าแรกของ Google สมัครเลย!
Slotpg ที่สุดของเว็บไซต์สล็อตออนไลน์ไม่ผ่านเอเย่นต์ การันตีหน้าแรกของ Google สมัครเลย! สำหรับFullslotกิจกรรมกงล้อเครดิตนั้น หลายท่านน่าจะเคยเห็นผ่านตากันมาบ้างแล้ว เนื่องจากนี่เป็นกิจกรรมที่คุณสามารถรับและสะสมเพชรได้เรื่อยเลยนะครับ ถ้าเกิดคุณสามารถสะสมเพชรให้ครบ 1,000 เพชรได้ คุณก็จะหมุนกงล้อได้ 1 ครั้ง แล้วก็รับเครดิตฟรีจากวงล้อได้เลย แต่ว่าคุณต้องทำยอดให้ได้ 5 เท่าครับ ถึงจะสามารถถอนได้ 1 เท่า ซึ่งวิถีทางสำหรับเพื่อการสะสมเพชร
สำหรับFullslotกิจกรรมกงล้อเครดิตนั้น หลายท่านน่าจะเคยเห็นผ่านตากันมาบ้างแล้ว เนื่องจากนี่เป็นกิจกรรมที่คุณสามารถรับและสะสมเพชรได้เรื่อยเลยนะครับ ถ้าเกิดคุณสามารถสะสมเพชรให้ครบ 1,000 เพชรได้ คุณก็จะหมุนกงล้อได้ 1 ครั้ง แล้วก็รับเครดิตฟรีจากวงล้อได้เลย แต่ว่าคุณต้องทำยอดให้ได้ 5 เท่าครับ ถึงจะสามารถถอนได้ 1 เท่า ซึ่งวิถีทางสำหรับเพื่อการสะสมเพชร pg slot game slotpg Fullslotpg.win 29 MAR 67 Jenifer คาสิโนออนไลน์ slotpgมาแรงที่สุด Top 70
pg slot game slotpg Fullslotpg.win 29 MAR 67 Jenifer คาสิโนออนไลน์ slotpgมาแรงที่สุด Top 70 รับโปรโมชั่นสล็อตออนไลน์เพิ่มเครดิตทำเงินเยอะขึ้นเรื่อยๆ
รับโปรโมชั่นสล็อตออนไลน์เพิ่มเครดิตทำเงินเยอะขึ้นเรื่อยๆ

 FULLSLOTPG
FULLSLOTPG  3. ภาพงามตาแตก
3. ภาพงามตาแตก 4. เสียงประกอบดึงอารมณ์
4. เสียงประกอบดึงอารมณ์ ดาวน์โหลด Pg slot fullslot fullslotpg.in 23 มกรา 2567 Rob จ่ายจริง pg สล็อตแจกจริง Top 77
ดาวน์โหลด Pg slot fullslot fullslotpg.in 23 มกรา 2567 Rob จ่ายจริง pg สล็อตแจกจริง Top 77 1. สล็อต โปรโมชั่นสมาชิกใหม่ 40%
1. สล็อต โปรโมชั่นสมาชิกใหม่ 40%


 เว็บหวยออนไลน์ลาวที่ดีรวมทั้งคุ้มเยอะที่สุด ผู้เล่นทุกคนควรรู้ก่อนเริ่มแทงหวยจริง ทำเงินเยอะขึ้นแบบง่ายๆ
เว็บหวยออนไลน์ลาวที่ดีรวมทั้งคุ้มเยอะที่สุด ผู้เล่นทุกคนควรรู้ก่อนเริ่มแทงหวยจริง ทำเงินเยอะขึ้นแบบง่ายๆ ทำความรู้จักหวยออนไลน์ลาว แทงง่าย ถูกรางวัลได้มากที่สุด
ทำความรู้จักหวยออนไลน์ลาว แทงง่าย ถูกรางวัลได้มากที่สุด

 เกมสล็อตออนไลน์แต่ละเว็บไซต์เช่นเดียวกันจริงมั้ย ?
เกมสล็อตออนไลน์แต่ละเว็บไซต์เช่นเดียวกันจริงมั้ย ?
 สล็อตเว็บตรงไม่ผ่านเอเย่นต์ สล็อตเว็บตรงลิขสิทธิ์แท้จากค่าย PG SLOT
สล็อตเว็บตรงไม่ผ่านเอเย่นต์ สล็อตเว็บตรงลิขสิทธิ์แท้จากค่าย PG SLOT 

 • มีใบ Certificate รวมทั้ง License ยืนยันลิขสิทธิ์แท้ และก็ถ้าหากจะให้ดีควรมีหนังสือรับรองหรือเอกสารยืนยันความเป็นเว็บตรง ของเว็บนั้นๆด้วย เพื่อเป็นตัวยืนยันว่าพวกเราเป็นของจริงแล้วก็ pgslot pg เป็นค่ายที่เกื้อหนุนเว็บของเราอยู่โดยตรง
• มีใบ Certificate รวมทั้ง License ยืนยันลิขสิทธิ์แท้ และก็ถ้าหากจะให้ดีควรมีหนังสือรับรองหรือเอกสารยืนยันความเป็นเว็บตรง ของเว็บนั้นๆด้วย เพื่อเป็นตัวยืนยันว่าพวกเราเป็นของจริงแล้วก็ pgslot pg เป็นค่ายที่เกื้อหนุนเว็บของเราอยู่โดยตรง

 สล็อต สารภาพกระบวนการทำธุรกรรมฝากเบิกเงินโดยไม่มีอย่างต่ำ นี่เป็นสิ่งที่ได้เปรียบสำหรับผู้เล่นที่ไม่ต้องการที่จะอยากลงทุนมากหรือมีงบประมาณจำกัด คุณสามารถฝากเงินเพียงแค่เล็กๆน้อยๆรวมทั้งเริ่มเล่นเกมสล็อตที่คุณรู้สึกชื่นชอบได้ทันที
สล็อต สารภาพกระบวนการทำธุรกรรมฝากเบิกเงินโดยไม่มีอย่างต่ำ นี่เป็นสิ่งที่ได้เปรียบสำหรับผู้เล่นที่ไม่ต้องการที่จะอยากลงทุนมากหรือมีงบประมาณจำกัด คุณสามารถฝากเงินเพียงแค่เล็กๆน้อยๆรวมทั้งเริ่มเล่นเกมสล็อตที่คุณรู้สึกชื่นชอบได้ทันที PG Slot ตั้งใจจริงสำหรับเพื่อการให้บริการแก่ผู้เล่นอย่างแน่วแน่และก็ไม่เป็นอันตราย มีระบบระเบียบรักษาความปลอดภัยที่เข้มงวดเพื่อให้ข้อมูลและก็เงินของผู้เล่นไม่มีอันตรายตลอดเวลา
PG Slot ตั้งใจจริงสำหรับเพื่อการให้บริการแก่ผู้เล่นอย่างแน่วแน่และก็ไม่เป็นอันตราย มีระบบระเบียบรักษาความปลอดภัยที่เข้มงวดเพื่อให้ข้อมูลและก็เงินของผู้เล่นไม่มีอันตรายตลอดเวลา 

 • เราเป็นคาสิโนเว็บไซต์ตรง เว็บไซต์พนันออนไลน์ที่ดีที่สุด เว้นเสียแต่ที่ว่าเรามีประสบการณ์การเปิดให้บริการคาสิโนออนไลน์มากว่า 10 ปี แล้ว ในไทยมีใครให้เป็นเวลายาวนานกว่านี้ไหม!?
• เราเป็นคาสิโนเว็บไซต์ตรง เว็บไซต์พนันออนไลน์ที่ดีที่สุด เว้นเสียแต่ที่ว่าเรามีประสบการณ์การเปิดให้บริการคาสิโนออนไลน์มากว่า 10 ปี แล้ว ในไทยมีใครให้เป็นเวลายาวนานกว่านี้ไหม!? อันที่จริงแล้วการจะสล็อตให้ปัง มิได้อยู่ที่สูตรซักเท่าไหร่ สล็อตออนไลน์จะปัง ขึ้นอยู่กับเว็บที่เล่น โดยเหตุนั้น การเล่นสล็อตกับเว็บไซต์ตรงจะยิ่งทำให้ท่านแตกง่ายขึ้น แต่ว่าเว็บตรงก็ยังมีหลายเกรด ได้แก่ เว็บบางเว็บประมูลระบบรุ่นเก่ามา ทำให้ระบบทั้งหมดทั้งปวงเป็นแบบอย่างล้าหลัง ไม่คดโกงจริง แต่ก็แตกยาก ไม่ลื่นไหลราวกับระบบใหม่ของเรา ดังนั้น การเลือกเว็บเล่นเป็นเรื่องสำคัญที่สุดสิ่งหนึ่ง สำหรับในการเล่นสล็อต เราก็เลยของชี้แนะให้ทุกคนเล่นกับพวกเรา ด้วยเหตุผลสำคัญๆดังต่อไปนี้!
อันที่จริงแล้วการจะสล็อตให้ปัง มิได้อยู่ที่สูตรซักเท่าไหร่ สล็อตออนไลน์จะปัง ขึ้นอยู่กับเว็บที่เล่น โดยเหตุนั้น การเล่นสล็อตกับเว็บไซต์ตรงจะยิ่งทำให้ท่านแตกง่ายขึ้น แต่ว่าเว็บตรงก็ยังมีหลายเกรด ได้แก่ เว็บบางเว็บประมูลระบบรุ่นเก่ามา ทำให้ระบบทั้งหมดทั้งปวงเป็นแบบอย่างล้าหลัง ไม่คดโกงจริง แต่ก็แตกยาก ไม่ลื่นไหลราวกับระบบใหม่ของเรา ดังนั้น การเลือกเว็บเล่นเป็นเรื่องสำคัญที่สุดสิ่งหนึ่ง สำหรับในการเล่นสล็อต เราก็เลยของชี้แนะให้ทุกคนเล่นกับพวกเรา ด้วยเหตุผลสำคัญๆดังต่อไปนี้! ขอขอบคุณreference
ขอขอบคุณreference  เกมสล็อตออนไลน์
เกมสล็อตออนไลน์  สิ่งที่แตกต่างระหว่างการเล่นสล็อต pg slot ของจริงกับสล็อตเอเย่นต์
สิ่งที่แตกต่างระหว่างการเล่นสล็อต pg slot ของจริงกับสล็อตเอเย่นต์ -สล็อตแท้มีแบบอย่างเกมที่นำสมัยกว่า เพราะค่ายเกมเขามานะปรับปรุงประสิทธิภาพของเกมให้มีความสนุกสนาน ปรับใหม่ เพื่อให้นำสมัยตอบปัญหาผู้เล่นตลอดระยะเวลา
-สล็อตแท้มีแบบอย่างเกมที่นำสมัยกว่า เพราะค่ายเกมเขามานะปรับปรุงประสิทธิภาพของเกมให้มีความสนุกสนาน ปรับใหม่ เพื่อให้นำสมัยตอบปัญหาผู้เล่นตลอดระยะเวลา